 Disciplines >
Disciplines >
 Analysis & Design >
Analysis & Design >
 Concepts >
Concurrency
Concepts >
Concurrency
Disciplines >
Analysis & Design >
Concepts >
Concurrency
Concepts:
|
| Note: Concurrency is discussed generally here, as it might apply to any system. However, concurrency is particularly important in systems that have to react to outside events in real-time and that often have hard deadlines to meet. To deal with the particular demands of this class of system, the Rational Unified Process (RUP) has Real-Time (Reactive) System Extensions. For more information on this topic, see Real-Time Systems. |
Concurrency is the tendency for things to happen at the same time in a system. Concurrency is a natural phenomenon, of course. In the real world, at any given time, many things are happening simultaneously. When we design software to monitor and control real-world systems, we must deal with this natural concurrency.
When dealing with concurrency issues in software systems, there are generally two aspects that are important: being able to detect and respond to external events occurring in a random order, and ensuring that these events are responded to in some minimum required interval.
If each concurrent activity evolved independently, in a truly parallel fashion, this would be relatively simple: we could simply create separate programs to deal with each activity. The challenges of designing concurrent systems arise mostly because of the interactions which happen between concurrent activities. When concurrent activities interact, some sort of coordination is required.
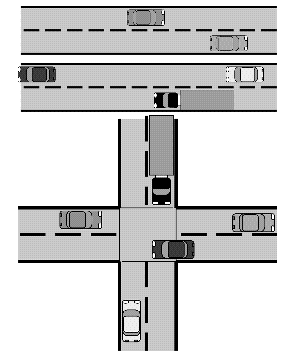
Figure 1: Example of concurrency at work: parallel activities that do not interact have simple concurrency issues. It is when parallel activities interact or share the same resources that concurrency issues become important.
Vehicular traffic provides a useful analogy. Parallel traffic streams on different roadways having little interaction cause few problems. Parallel streams in adjacent lanes require some coordination for safe interaction, but a much more severe type of interaction occurs at an intersection, where careful coordination is required.
Some of the driving forces for concurrency are external. That is, they are imposed by the demands of the environment. In real-world systems many things are happening simultaneously and must be addressed in real-time by software. To do so, many real-time software systems must be reactive. They must respond to externally generated events which may occur at somewhat random times, in some-what random order, or both.
Designing a conventional procedural program to deal with these situations is extremely complex. It can be much simpler to partition the system into concurrent software elements to deal with each of these events. The key phrase here is can be, since complexity is also affected by the degree of interaction between the events.
There can also be internally inspired reasons for concurrency [LEA97]. Performing tasks in parallel can substantially speed up the computational work of a system if multiple CPUs are available. Even within a single processor, multitasking can dramatically speed things up by preventing one activity from blocking another while waiting for I/O, for example. A common situation where this occurs is during the startup of a system. There are often many components, each of which requires time to be made ready for operation. Performing these operations sequentially can be painfully slow.
Controllability of the system can also be enhanced by concurrency. For example, one function can be started, stopped, or otherwise influenced in mid-stream by other concurrent functionssomething extremely difficult to accomplish without concurrent components.
With all these benefits, why dont we use concurrent programming everywhere?
Most computers and programming languages are inherently sequential. A procedure or processor executes one instruction at a time. Within a single sequential processor, the illusion of concurrency must be created by interleaving the execution of different tasks. The difficulties lie not so much in the mechanics of doing so, but in the determination of just when and how to interleave program segments which may interact with each other.
Although achieving concurrency is easy with multiple processors, the interactions become more complex. First there is the question of communication between tasks running on different processors. Usually there are several layers of software involved, which increase complexity and add timing overhead. Determinism is reduced in multi-CPU systems, since clocks and timing may differ, and components may fail independently.
Finally, concurrent systems can be more difficult to understand because they lack an explicit global system state. The state of a concurrent system is the aggregate of the states of its components.
As an example to illustrate the concepts to be discussed, we will use an elevator system. More precisely, we mean a computer system designed to control a group of elevators at one location in a building. Obviously there may be many things going on concurrently within a group of elevatorsor nothing at all! At any point in time someone on any floor may request an elevator, and other requests may be pending. Some of the elevators may be idle, while others are either carrying passengers, or going to answer a call, or both. Doors must open and close at appropriate times. Passengers may be obstructing the doors, or pressing door open or close buttons, or selecting floorsthen changing their minds. Displays need to be updated, motors need to be controlled, and so on, all under the supervision of the elevator control system. Overall, its a good model for exploring concurrency concepts, and one for which we share a reasonably common degree of understanding and a working vocabulary.
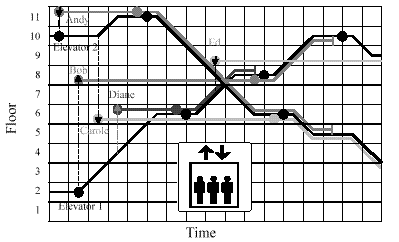
Figure 2: A scenario involving two elevators and five potential passengers distributed
over 11 floors.
As potential passengers place demands upon the system at different times, the system attempts to provide the best overall service by selecting elevators to answer calls based upon their current states and projected response times. For example, when the first potential passenger, Andy, calls for an elevator to go down, both are idle, so the closest one, Elevator 2, responds, although it must first travel upward to get to Andy. On the other hand, a few moments later when the second potential passenger, Bob, requests an elevator to go up, the more distant Elevator 1 responds, since it is known that Elevator 2 must travel downward to an as-yet-unknown destination before it can answer an up call from below.
If the elevator system only had one elevator and that elevator had only to serve one passenger at a time, we might be tempted to think we could handle it with an ordinary sequential program. Even for this simple case, the program would require many branches to accommodate different conditions. For example, if the passenger never boarded and selected a floor, we would want to reset the elevator to allow it to respond to another call.
The normal requirement to handle calls from multiple potential passengers and requests from multiple passengers exemplifies the external driving forces for concurrency we discussed earlier. Because the potential passengers lead their own concurrent lives, they place demands on the elevator at seemingly random times, no matter what the state of the elevator. It is extremely difficult to design a sequential program that can respond to any of these external events at any time while continuing to guide the elevator according to past decisions.
In order to design concurrent systems effectively, we must be able to reason about concurrencys role in the system, and in order to do this we need abstractions of concurrency itself.
The fundamental building blocks of concurrent systems are activities which proceed more or less independently of each other. A useful graphical abstraction for thinking about such activities is Buhrs timethreads. [BUH96] Our elevator scenario in Figure 3 actually used a form of them. Each activity is represented as a line along which the activity travels. The large dots represent places where an activity starts or waits for an event to occur before proceeding. One activity can trigger another to continue, which is represented in the timethread notation by touching the waiting place on the other timethread.
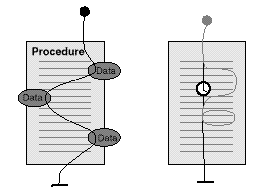
Figure 3: A visualization of threads of execution
The basic building blocks of software are procedures and data structures, but these alone are inadequate for reasoning about concurrency. As processor executes a procedure it follows a particular path depending upon current conditions. This path may be called the thread of execution or thread of control. This thread of control may take different branches or loops depending upon the conditions which exist at the time, and in real-time systems may pause for a specified period or wait for a scheduled time to resume.
From the point of view of the program designer, the thread of execution is controlled by the logic in the program and scheduled by the operating system. When the software designer chooses to have one procedure invoke others, the thread of execution jumps from one procedure to another, then jumping back to continue where it left off when a return statement is encountered.
From the point of view of the CPU, there is only one main thread of execution that weaves through the software, supplemented by short separate threads which are executed in response to hardware interrupts. Since everything else builds on this model, it is important for designers to know about it. Designers of real-time systems, to a greater degree than designers of other types of software, must understand how a system works at a very detailed level. This model, however, is at such a low level of abstraction that it can only represent concurrency very coarse granularitythat of the CPU. To design complex systems, it is useful to be able to work at various levels of abstraction. Abstraction, of course, is the creation of a view or model that suppresses unnecessary details so that we may focus on what is important to the problem at hand.
To move up one level, we commonly think of software in terms of layers. At the most fundamental level, the Operating System (OS) is layered between the hard-ware and the application software. It provides the application with hardware-based services, such as memory, timing, and I/O, but it abstracts the CPU to create a virtual machine that is independent of the actual hardware configuration.
To support concurrency, a system must provide for multiple threads of control. The abstraction of a thread of control can be implemented in a number of ways by hardware and software. The most common mechanisms are variations of one of the following [DEI84], [TAN86]:
When the operating system provides multitasking, a common unit of concurrency is the process. A process is an entity provided, supported and managed by the operating system whose sole purpose is to provide an environment in which to execute a program. The process provides a memory space for the exclusive use of its application program, a thread of execution for executing it, and perhaps some means for sending messages to and receiving them from other processes. In effect, the process is a virtual CPU for executing a concurrent piece of an application.
Each process has three possible states:
Processes are also often assigned relative priorities. The operating system kernel determines which process to run at any given time based upon their states, their priorities, and some scheduling policy. Multitasking operating systems actually share a single thread of control among all of their processes.
Note: The terms 'task' and 'process' are often used interchangeably. Unfortunately, the term 'multitasking' is generally used to mean the ability to manage multiple processes at once, while 'multiprocessing' refers to a system with multiple processors (CPUs). We adhere to this convention because it is the most commonly accepted. However, we use the term 'task' sparingly, and when we do, it is to make a fine distinction between the unit of work being done (the task) and the entity which provides the resources and environment for it (the process).
As we said before, from the point of view of the CPU, there is only one thread of execution. Just as an application program can jump from one procedure to another by invoking subroutines, the operating system can transfer control from one process to another on the occurrence of an interrupt, the completion of a procedure, or some other event. Because of the memory protection afforded by a process, this task switching can carry with it considerable overhead. Furthermore, because the scheduling policy and process states have little to do with the application viewpoint, the interleaving of processes is usually too low a level of abstraction for thinking about the kind of concurrency which is important to the application.
In order to reason clearly about concurrency, it is important to maintain a clear separation between the concept of a thread of execution and that of task switching. Each process can be thought of as maintaining its own thread of execution. When the operating system switches between processes, one thread of execution is temporarily interrupted and another starts or resumes where it previously left off.
Many operating systems, particularly those used for real-time applications, offer a lighter weight alternative to processes, called threads or lightweight threads.
Threads are a way of achieving a slightly finer granularity of concurrency within a process. Each thread belongs to a single process, and all the threads in a process share the single memory space and other resources controlled by that process.
Usually each thread is assigned a procedure to execute.
Note: It is unfortunate that the term 'threads' is overloaded. When we use the word 'thread' by itself, as we do here, we are referring to a 'physical thread' provided and managed by the operating system. When we refer to a 'thread of execution', or 'thread of control' or 'timethread' as in the foregoing discussion, we mean an abstraction which is not necessarily associated with a physical thread.
Of course, multiple processors offer the opportunity for truly concurrent execution. Most commonly, each task is permanently assigned to a process in a particular processor, but under some circumstances tasks can be dynamically assigned to the next available processor. Perhaps the most accessible way of doing this is by using a symmetric multiprocessor. In such a hardware configuration, multiple CPUs can access memory through a common bus.
Operating systems which support symmetric multiprocessors can dynamically assign threads to any available CPU. Examples of operating systems which support symmetric multiprocessors are SUNs Solaris and Microsofts Windows NT.
Earlier we made the seemingly paradoxical assertions that concurrency both increases and decreases the complexity of software. Concurrent software provides simpler solutions to complex problems primarily because it permits a separation of concerns among concurrent activities. In this respect, concurrency is just one more tool with which to increase the modularity of software. When a system must perform predominantly independent activities or respond to predominantly independent events, assigning them to individual concurrent components naturally simplifies design.
The additional complexities associated with concurrent software arise almost entirely from the situations where these concurrent activities are almost but not quite independent. In other words, the complexities arise from their interactions. From a practical standpoint, interactions between asynchronous activities invariably involve the exchange of some form of signals or information. Interactions between concurrent threads of control give rise to a set of issues which are unique to concurrent systems, and which must be addressed to guarantee that a system will behave correctly.
Although there are many different specific realizations of inter-process communication (IPC) or inter-thread communication mechanisms, they can all be ultimately classified into two categories:
In asynchronous communication the sending activity forwards its information regardless of whether the receiver is ready to receive it or not. After launching the information on its way, the sender proceeds with whatever else it needs to do next. If the receiver is not ready to receive the information, the information is put on some queue where the receiver can retrieve it later. Both the sender and receiver operate asynchronously of each other, and hence cannot make assumptions about each others state. Asynchronous communication is often called message passing.
Synchronous communication includes synchronization between the sender and the receiver in addition to the exchange of information. During the exchange of information, the two concurrent activities merge with each other executing, in effect, a shared segment of code, and then split up again when the communication is complete. Thus, during that interval, they are synchronized with each other and immune to concurrency conflicts with each other. If one activity (sender or receiver) is ready to communicate before the other, it will be suspended until the other one becomes ready as well. For this reason, this mode of communication is sometimes referred to as rendezvous.
A potential problem with synchronous communication is that, while waiting on its peer to be ready, an activity is not capable of reacting to any other events. For many real-time systems, this is not always acceptable because it may not be possible to guarantee timely response to an important situation. Another drawback is that it is prone to deadlock. A deadlock occurs when two or more activities are involved in a vicious circle of waiting on each other.
When interactions are necessary between concurrent activities, the designer must choose between a synchronous or asynchronous style. By synchronous, we mean that two or more concurrent threads of control must rendezvous at a single point in time. This generally means that one thread of control must wait for another to respond to a request. The simplest and most common form of synchronous interaction occurs when concurrent activity A requires information from concurrent activity B in order to proceed with As own work.
Synchronous interactions are, of course, the norm for non-concurrent software components. Ordinary procedure calls are a prime example of a synchronous interaction: when one procedure calls another, the caller instantaneously transfers control to the called procedure and effectively waits for control to be transferred back to it. In the concurrent world, however, additional apparatus is needed to synchronize otherwise independent threads of control.
Asynchronous interactions do not require a rendezvous in time, but still require some additional apparatus to support the communication between two threads of control. Often this apparatus takes the form of communication channels with message queues so that messages can be sent and received asynchronously.
Note that a single application may mix synchronous and asynchronous communication, depending on whether it needs to wait for a response or has other work it can do while the message receiver is processing the message.
Keep in mind that true concurrency of processes or threads is only possible on multipocessors with concurrent execution of processes or threads; on a uni-processor the illusion of simultaneous execution of threads or processes is created by the operating system scheduler, which slices the available processing resources into small chunks so that it appears that several threads or processes are executing concurrently. A poor design will defeat this time slicing by creating multiple processes or threads which communicate frequently and synchronously, causing processes or threads to spend much of their "time slice" effectively blocked and waiting for a response from another process or thread.
Concurrent activities may depend upon scarce resources which must be shared among them. Typical examples are I/O devices. If an activity requires a resource which is being used by another activity, it must wait its turn.
Perhaps the most fundamental issue of concurrent system design is the avoidance of race conditions. When part of a system must perform state-dependent functions (that is, functions whose results depend upon the present state of the system), it must be assured that that state is stable during the operation. In other words, certain operations must be atomic. Whenever two or more threads of control have access to the same state information, some form of concurrency control is necessary to assure that one thread does not modify the state while the other is performing an atomic state-dependent operation. Simultaneous attempts to access the same state information which could make the state internally inconsistent are called race conditions.
A typical example of a race condition could easily occur in the elevator system when a floor is selected by a passenger. Our elevator works with lists of floors to be visited when traveling in each direction, up and down. Whenever the elevator arrives at a floor, one thread of control removes that floor from the appropriate list and gets the next destination from the list. If the list is empty, the elevator either changes direction if the other list contains floors, or goes idle if both lists are empty. Another thread of control is responsible for putting floor requests in the appropriate list when the passengers select their floors. Each thread is performing combinations of operations on the list which are not inherently atomic: for example, checking the next available slot then populating the slot. If the threads happen to interleave their operations, they can easily overwrite the same slot in the list.
Deadlock is a condition in which two threads of control are each blocked, each waiting for the other to take some action. Ironically, deadlock often arises because we apply some synchronization mechanism to avoid race conditions.
The elevator example of a race condition could easily cause a relatively benign case of deadlock. The elevator control thread thinks the list is empty and, thus, never visits another floor. The floor request thread thinks the elevator is working on emptying the list and therefore that it need not notify the elevator to leave the idle state.
In addition to the fundamental issues, there are some practical issues which must be explicitly addressed in the design of concurrent software.
Within a single CPU, the mechanisms required to simulate concurrency by switching between tasks use CPU cycles which could otherwise be spent on the application itself. On the other hand, if software must wait for I/O devices, for example, the performance improvements afforded by concurrency may greatly outweigh any added overhead.
Concurrent software requires coordination and control mechanisms not needed in sequential programming applications. These make concurrent software more complex and increase the opportunities for errors. Problems in concurrent systems are also inherently more difficult to diagnose because of the multiple threads of control. On the other hand, as we have pointed out before, when the external driving forces are themselves concurrent, concurrent software which handles different events independently can be vastly simpler than a sequential program which must accommodate the events in arbitrary order.
Because many factors determine the interleaving of execution of concurrent components, the same software may respond to the same sequence of events in a different order. Depending upon the design, such changes in order may produce different results.
Application software may or may not be involved in the implementation of concurrency control. There is a whole spectrum of possibilities, including, in order of increasing involvement:
These possibilities are neither an exhaustive set, nor are they mutually exclusive. In a given system a combination of them may be employed.
A common mistake in concurrent system design is to select the specific mechanisms to be used for concurrency too early in the design process. Each mechanism brings with it certain advantages and disadvantages, and the selection of the best mechanism for a particular situation is often determined by subtle trade-offs and compromises. The earlier a mechanism is chosen, the less information one has upon which to base the selection. Nailing down the mechanism also tends to reduce the flexibility and adaptability of the design to different situations.
As with most complex design tasks, concurrency is best understood by employing multiple levels of abstraction. First, the functional requirements of the system must be well understood in terms of its desired behavior. Next the possible roles for concurrency should be explored. This is best done using the abstraction of threads without committing to a particular implementation. To the extent possible, the final selection of mechanisms for realizing the concurrency should remain open to allow fine tuning of performance and the flexibility to distribute components differently for various product configurations.
The conceptual distance between the problem domain (e.g., an elevator system) and the solution domain (software constructs) remains one of the biggest difficulties in system design. Visual formalisms are extremely helpful for understanding and communicating complex ideas such as concurrent behavior, and, in effect, bridging that conceptual gap. Among the tools which have proven valuable for such problems are:
To design a concurrent software system, we must combine the building blocks of software (procedures and data structures) with the building blocks of concurrency (threads of control). We have discussed the concept of a concurrent activity, but one doesnt construct systems from activities. One constructs systems from components, and it makes sense to construct concurrent systems from concurrent components. Taken by themselves, neither procedures nor data structures nor threads of control make very natural models for concurrent components, but objects seem like a very natural way to combine all of these necessary elements into one neat package.
An object packages procedures and data structures into a cohesive component with its own state and behavior. It encapsulates the specific implementation of that state and behavior and defines an interface by which other objects or software may interact with it. Objects generally model real world entities or concepts, and interact with other objects by exchanging messages. They are now well accepted by many as the best way to construct complex systems.
Figure 4: A simple set of objects for the elevator system.
Consider an object model for our elevator system. A call station object at each
floor monitors the up and down call buttons at that floor. When a prospective
passenger depresses a button, the call station object responds by sending a
message to an elevator dispatcher object, which selects the elevator most likely
to provide the fastest service, dispatches the elevator and acknowledges the
call. Each elevator object concurrently and independently controls its physical
elevator counterpart, responding to passenger floor selections and calls from
the dispatcher.
Concurrency can take two forms in such an object model. Inter-object concurrency results when two or more objects are performing activities independently via separate threads of control. Intra-object concurrency arises when multiple threads of control are active in a single object. In most object-oriented languages today, objects are passive, having no thread of control of their own. The thread(s) of control must be provided by an external environment. Most commonly, the environment is a standard OS process created to run an object-oriented program written in a language like C++ or Smalltalk. If the OS supports multi-threading, multiple threads can be active in the same or different objects.
In the figure below, the passive objects are represented by the circular elements. The shaded interior area of each object is its state information, and the segmented outer ring is the set of procedures (methods) which define the objects behavior.
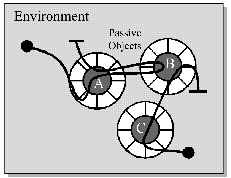
Figure 5: Illustration of object interaction.
Intra-object concurrency brings with it all of the challenges of concurrent software, such as the potential for race conditions when multiple threads of control have access to the same memory spacein this case, the data encapsulated in the object. One might have thought that data encapsulation would provide a solution to this issue. The problem, of course, is that the object does not encapsulate the thread of control. Although inter-object concurrency avoids these issues for the most part, there is still one troublesome problem. In order for two concurrent objects to interact by exchanging messages, at least two threads of control must handle the message and access the same memory space in order to hand it off. A related (but still more difficult) problem is that of distribution of objects among different processes or even processors. Messages between objects in different processes requires support for interprocess communication, and generally require the message to be encoded and decoded into data that can be passed across the process boundaries.
None of these problems is insurmountable, of course. In fact, as we pointed out in the previous section, every concurrent system must deal with them, so there are proven solutions. It is just that concurrency control causes extra work and introduces extra opportunities for error. Furthermore, it obscures the essence of the application problem. For all of these reasons, we want to minimize the need for application programmers to deal with it explicitly. One way to accomplish this is to build an object-oriented environment with support for message passing between concurrent objects (including concurrency control), and minimize or eliminate the use of multiple threads of control within a single object. In effect, this encapsulates the thread of control along with the data.
Objects with their own threads of control are called active objects. In order to support asynchronous communication with other active objects, each active object is provided with a message queue or mailbox. When an object is created, the environment gives it its own thread of control, which the object encapsulates until it dies. Like a passive object, the active object is idle until the arrival of a message from outside. The object executes whatever code is appropriate to process the message. Any messages which arrive while the object is busy are enqueued in the mailbox. When the object completes the processing of a message, it returns to pick up the next waiting message in the mailbox, or waits for one to arrive. Good candidates for active objects in the elevator system include the elevators themselves, the call stations on each floor, and the dispatcher.
Depending upon their implementation, active objects can be made to be quite efficient. They do carry somewhat more overhead, however, than a passive object. Thus, since not every operation need be concurrent, it is common to mix active and passive objects in the same system. Because of their different styles of communication, it is difficult to make them peers, but an active object makes an ideal environment for passive objects, replacing the OS process we used earlier. In fact, if the active object delegates all of the work to passive objects, it is basically the equivalent of an OS process or thread with interprocess communication facilities. More interesting active objects, however, have behavior of their own to do part of the work, delegating other parts to passive objects.
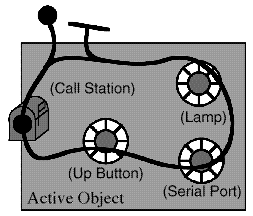
Figure 6: An 'active' object provides an environment for passive classes
Good candidates for passive objects inside an active elevator object include a list of floors at which the elevator must stop while going up and another list for going down. The elevator should be able to ask the list for the next stop, add new stops to the list, and remove stops which have been satisfied.
Because complex systems are almost always constructed of subsystems several levels deep before getting to leaf-level components, it is a natural extension to the active object model to permit active objects to contain other active objects.
Although a single-threaded active object does not support true intra-object concurrency, delegating work to contained active objects is a reasonable substitute for many applications. It retains the important advantage of complete encapsulation of state, behavior, and thread of control on a per-object basis, which simplifies the concurrency control issues.
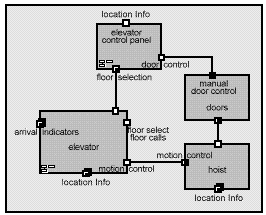
Figure 7: The elevator system, showing nested active objects
Consider, for example, the partial elevator system depicted above. Each elevator has doors, a hoist, and a control panel. Each of these components is well-modeled by a concurrent active object, where the door object controls the opening and closing of the elevator doors, the hoist object controls the positioning of the elevator through the mechanical hoist, and the control panel object monitors the floor selection buttons and door open/close buttons. Encapsulating the concurrent threads of control as active objects leads to much simpler software than could be achieved if all this behavior were managed by a single thread of control.
As we said when discussing race conditions, in order for a system to behave in a correct and predictable manner, certain state-dependent operations must be atomic.
For an object to behave properly, it is certainly necessary for its state to be internally consistent before and after processing any message. During the processing of a message, the objects state may be in a transient condition and may be indeterminate because operations may be only partially complete.
If an object always completes its response to one message before responding to another, the transient condition is not a problem. Interrupting one object to execute another also poses no problem because each object practices strict encapsulation of its state. (Strictly speaking, this is not completely true, as we'll explain soon.)
Any circumstance under which an object interrupts the processing of a message to process another opens the possibility of race conditions and, thus, requires the use of concurrency controls. This, in turn, opens the possibility of deadlock.
Concurrent design is generally simpler, therefore, if objects process each message to completion before accepting another. This behavior is implicit in the particular form of active object model we have presented.
The issue of consistent state can manifest itself in two different forms in concurrent systems, and these are perhaps easier to understand in terms of object-oriented concurrent systems. The first form is that which we have already discussed. If the state of a single object (passive or active) is accessible to more than one thread of control, atomic operations must be protected either by the natural atomicity of elementary CPU operations or by a concurrency control mechanism.
The second form of the consistent state issue is perhaps more subtle. If more than one object (active or passive) contains the same state information, the objects will inevitably disagree about the state for at least short intervals of time. In a poor design they may disagree for longer periodseven forever. This manifestation of inconsistent state can be considered a mathematical dual of the other form.
For example, the elevator motion control system (the hoist) must assure that the doors are closed and cannot open before the elevator can move. A design without proper safeguards could permit the doors to open in response to a passenger hitting the door open button just as the elevator begins to move.
It may seem that an easy solution to this problem is to permit state information to reside in only one object. Although this may help, it can also have a detrimental impact on performance, particularly in a distributed system. Furthermore, it is not a foolproof solution. Even if only one object contains certain state information, as long as other concurrent objects make decisions based upon that state at a certain point in time, state changes can invalidate the decisions of other objects.
There is no magic solution to the problem of consistent state. All practical solutions require us to identify atomic operations and protect them with some sort of synchronization mechanism which blocks concurrent access for tolerably short periods of time. Tolerably short is very much context dependent. It may be as long as it takes the CPU to store all the bytes in a floating point number, or it may be as long as it takes the elevator to travel to the next stop.
|
Rational Unified
Process
|