The Java interface to ObjectStore supports rawfs databases. For information about rawfs databases, see the book ObjectStore Management.
Opening and Closing a Database
Performing Garbage Collection in a Database
Schema Evolution: Modifying Class Definitions of Objects in a Database
Obtaining Information About a Database
Implementing Cross-Segment References for Optimum Performance
Database Operations and Transactions
Upgrading Databases for Use with the JDK 1.2
Creating a Database
The Database class is an abstract class that represents a database. When you create a database,
This section discusses the following topics:
public static Database create(String name, int fileMode)ObjectStore throws AccessViolationException if the access mode does not provide owner write access.
import COM.odi.*;
class DbTest {
void test() {
Database db = Database.create("objectsrus.odb",
ObjectStore.OWNER_WRITE);
...
}
}
This example creates an instance of Database and stores a reference to the instance in the variable named db. The Database.create method is called with two parameters.The first parameter specifies the pathname of a file. The path can specify a relative name or a fully qualified name. It must always specify a file that is one of the following:
The second parameter specifies the access mode for the database.
For each database you create, ObjectStore creates an instance of Database to represent your database. Each database is associated with one instance of Database. Consequently, you can use the == operator to determine whether or not two Database objects in the same session represent the same database, for example, the following method returns true:
boolean checkIdentity(String dbname) {
Database db = Database.create(dbname,
ObjectStore.OWNER_WRITE);
Database dbAgain = Database.open(dbname,
ObjectStore.UPDATE);
return (db == dbAgain);
}
If you want to refer to a database on a remote host for which there is no local mount point, you can use a Server host prefix. This is the name of the remote host followed by a colon (:), as in oak:/foo/bar.odb or jackhammer:c:\bob\mydb.odb. On Windows, you can also use UNC pathnames, as in \\oak\c\foo\bar.odb.
Also, you can use locator files to allow access to additional hosts. See ObjectStore Management for information.
try {
Database.open(dbName, ObjectStore.UPDATE).destroy();
} catch(DatabaseNotFoundException e) {
}
Creating Segments
ObjectStore creates each database with one segment that you can use to store objects. A segment is a variable-sized region of disk space that ObjectStore uses to cluster objects stored in the database. Initially, the size of the segment is about 3 K. As you store additional objects in the segment, ObjectStore increases the size of the segment automatically.
The initial segment in a database is the default segment. To change the default segment, invoke the Database.setDefaultSegment() method.
To lock all objects in a segment, see Locking Objects, Segments, and Databases to Ensure Access.
For additional information about segments, see Managing Databases in Chapter 1 of ObjectStore Management.
Storing Objects in a Particular Segment
You can store objects in different segments by changing which segment is the default segment or by explicitly storing an object in a particular segment. Distributing objects can improve performance, but the following tradeoffs must be considered:
Determining If a Database or Segment Is Transient
Sometimes there are Java peer objects that identify C++ objects that have been transiently allocated. ObjectStore stores these C++ objects in the transient database and transient segment. Java primary objects are never in the transient database or transient segment, even if they are transient. ObjectStore creates transient segments as part of some peer object operations. You cannot use ObjectStore to create or manipulate transient segments.
CPlusPlus.getTransientSegment() == segment CPlusPlus.getTransientDatabase() == database
public DatabaseSegmentEnumeration getSegments()This method returns a DatabaseSegmentEnumeration object. After you have this object, you can use these methods to iterate over the segments in the enumeration:
After you create an enumeration, a segment in the enumeration might be destroyed. If you use the enumeration to try to access a destroyed segment, ObjectStore skips the destroyed segment. However, if you retrieve a segment with DatabaseSegmentEnumeration.nextElement() or nextSegment() and then the segment is destroyed, ObjectStore throws SegmentNotFoundException if you try to use the destroyed segment.
This section discusses the following topics:
When you create a database, ObjectStore creates and opens the database. To open an existing database, call the static Database.open() method. The method signature is
public static Database open(String name, int openMode)For example:
Database db = Database.open("myDb.odb",
ObjectStore.READONLY);
The first parameter specifies the pathname of your database. The second parameter indicates the open mode of the database.
db.open(ObjectStore.READONLY);You can use the static class open() method this way:
db = Database.open("myDb.odb", ObjectStore.READONLY);
Typically, both lines cause the same result. However, they might cause different results if a database has been destroyed and recreated. To recover the database, open it for update. This automatically recovers the database if necessary. Alternatively, you can run the osjcheckdb utility with the -openUpdateForRecovery option.
To lock all objects in a database, see Locking Objects, Segments, and Databases to Ensure Access.
Opening the Same Database Multiple Times
Each subsequent opening of a database after the initial open operation returns the same database object. For example:
db1 = Database.open("foo", ObjectStore.UPDATE);
db2 = Database.open("foo", ObjectStore.UPDATE);
The expression db1 == db2 returns true. They refer to the same database object. Consequently, a call to db1.close() or db2.close() closes the same database. No matter how many times you open a database, a single call to the close() method closes the database. (This is different in the C++ interface to ObjectStore. In that interface, for example, if you call open() four times and close() three times all on the same database, the database is still open.)
db.close();You cannot close a database when a transaction is in progress. The database you want to close must be open.
public void close(boolean retainAsTransient)Specify true to make retained objects transient. If you specify false, it is the same as calling the close() method without an argument. All access to retained objects ends.
Suppose you close a database and make retained objects transient. In the next transaction, if you reread an object from the database that you retained as a transient object, you then have two separate copies of the same object. One object is transient and one object is persistent. You do not have two references to a single object. When you close a database, all object identity is gone. After you close a database, the database is still associated with the session in which it was closed.
import COM.odi.*;
public class Goo {
public static void main(String[] args) {
Session session = Session.create(null, null);
session.join();
try {
try {
Database db = Database.create("my.odb", 0664);
db.close();
} catch (DatabaseAlreadyExistsException e) {
}
Database db1 = Database.open("my.odb",
ObjectStore.READONLY);
db1.close();
Database db2 = Database.open("my.odb",
ObjectStore.READONLY);
System.out.println(db1 == db2);
} finally {
session.terminate();
}
}
}
If you run a program with the previous code, the system displays true.In general, it is best to leave databases open for the entire session and write your application so that it shuts down ObjectStore before it exits.
However, keeping databases open consumes some ObjectStore Server resources. Also, there is a limit to the number of databases the ObjectStore Server can keep open at one time. This depends on the number of open files that the operating system permits, which varies by platform.
If you know the name of a database that has been automatically opened, you can use Database.open() to obtain the already open database. Another way to obtain a handle to an automatically opened database is to call Database.of() on an object from the automatically opened database.
If you do not close a database that ObjectStore automatically opens, ObjectStore closes it when you shut down ObjectStore.
Disabling autoopen
You can disable the ability of ObjectStore to automatically open databases. Call the ObjectStore.setAutoOpenMode() method and specify the ObjectStore.DISABLE_AUTO_OPEN constant. If you do disable automatic opens and your application tries to follow a reference to an unopened database, you receive DatabaseNotOpenException. Objects in Closed Databases
Objects in a closed database are not accessible. However, if you close a database with an argument of true, ObjectStore retains the persistent objects as transient objects.
Moving or Copying a Database
You can use the ObjectStore utilities oscopy and osmv to copy and move a database. See ObjectStore Management for information.
You can move or copy databases among different supported platforms.
Performing Garbage Collection in a Database
The ObjectStore persistent garbage collector (GC) collects unreferenced Java objects and ObjectStore collections in an ObjectStore database. Persistent garbage collection frees storage associated with objects that are unreachable. It does not move remaining objects to make the free space contiguous. Contents
This section discusses these topics:
Applications can continue to use a database while persistent GC is in progress. GC locks portions of a segment as needed, as if it were just another application. In this way, the GC minimizes the number of pages that are locked and the duration for which the locks are held. Also, the GC retries operations when it detects lock conflicts.
By default, the GC runs with a transaction priority of zero. Consequently, it is the preferred victim when the Server must terminate a transaction to resolve a deadlock. At a later time, the GC redoes the work that was lost when the transaction was aborted.
The GC uses read and write lock timeouts of short duration. This avoids competition with other processes for locks. If the GC cannot acquire a lock because of a timeout, it retries the operation at a later time.
The GC performs its job in two major phases. In the mark phase, the GC identifies the unreachable objects. In the sweep phase, the GC frees the storage used by the unreachable objects.
A segment is the smallest storage unit that can be garbage collected. You can specify a segment or a database to be garbage collected. It is usually best to avoid destroying strings (or objects) altogether and let the persistent garbage collector take care of destroying such unreachable objects. The persistent garbage collector can typically destroy and reclaim such objects very efficiently, since it can batch such operations and cluster them effectively. If you set up the GC to run when the system is lightly loaded, you can effectively defer the overhead of the destroy operations to a time when your system would otherwise be idle, thus getting greater real throughput from your application when you really need it.
The persistent GC never removes tombstones for exported objects. For unexported objects, the GC treats tombstones the same way that it treats other objects. The GC removes tombstones if they are not referenced. In other words, the GC removes only unreferenced tombstones. This behavior preserves the safe detection of bad references.
public java.util.Properties GC(java.util.Properties GCproperties)For the GCproperties parameter, specify null or a Properties object for the garbage collection operation. The properties are described in the next section as they are the same for Segment.GC(). If the GCproperties parameter is null, ObjectStore uses the default properties as defined in the documentation for Segment.GC(). The properties you can specify are the same as the properties for Segment.GC().
public java.util.Properties GC(java.util.Properties GCproperties)A transaction must not be in progress for the current session. The database that contains the segment you want to garbage collect must not be open for the current session. You cannot perform GC on the transient segment. If you try to, ObjectStore throws SegmentException.However, you must open it to create a Database object to represent it. After you close the database you want to garbage collect, you can call Database.GC() on the Database object that represents your closed database.
The GCproperties parameter specifies a list of GC properties or null. When you specify null, ObjectStore checks the system properties and uses the default properties, which are suitable for most operations. For more control over GC, you can specify one or more of the following properties. ObjectStore uses the default for any property you do not specify.
Running osgc on C++ Databases or Segments
You can run the osgc utility on C++ databases and segments, but you must observe the following restrictions:
- Associate such objects with database roots.
- Make such objects the targets of protected references. (A protected reference uses os_reference_protected.)
The osgc utility recognizes as reachable and, so, never collects objects that are associated with database roots and objects that are the targets of protected references.
There are primarily two ways to evolve schema:
Use the serialization technique with the sample code provided only when the database you want to evolve fits into heap space. When you use the serialization technique, the database cannot contain ObjectStore collections because they are not serializable.
The topics discussed in this section are
If you change the type that is associated with a persistent instance field, ObjectStore performs a default initialization, except in cases where both the old and new instance fields are of the following primitive types: byte, short, int, float, or double. In this case, ObjectStore applies the appropriate narrowing or widening conversion to the old value and assigns that value to the new instance field. Conversions that involve the long type cause ObjectStore to perform a default initialization on the new field.
Inheritance
You cannot use schema evolution to change the inheritance hierarchy of a class by adding, removing, or changing a superclass. Allowed changes
You can make the following changes to your class and you are not required to evolve the schema:
If a class (including its superclasses) has at least one indexable field, schema evolution is not required if you add indexes to other fields.
If the database contains collections that use indexes, you must drop the indexes before you perform schema evolution. After you evolve the schema, you can restore the indexes on the collection.
void evolveSchema(String dbName,
String workdbName,
PersistentTypeSummary summary)
The dbName parameter specifies the database whose schema you want to evolve. During schema evolution, this database is not available to any other operation.The workdbName parameter specifies the name of a database that ObjectStore uses to hold a checkpoint version of the database while schema evolution progresses. ObjectStore creates this database as part of schema evolution and destroys it when schema evolution is complete. This working database allows ObjectStore to resume schema evolution if it is interrupted. For example, an interruption can be caused by a power failure or a lack of disk space.
The summary parameter specifies a PersistentTypeSummary object that identifies the classes whose definitions have changed. It is permissible for the summary to include types that have not changed. However, if the summary does not include a type that has changed, that type might not be evolved.
Typically, you create the summary object as follows:
ObjectStore can evolve only one database at a time. This means that if there are cross-database references, only one database at a time is unavailable to other operations.
When you perform schema evolution on a particular class, you must provide definitions for all superclasses that are part of the schema for the database being evolved.
serialver DumpReload$LinkedListFor simplicity, the sample code includes this field.DumpReload$LinkedList: static final long serialVersionUID =-5286408624542393371L;
import COM.odi.*;
import COM.odi.util.OSHashtable;
import COM.odi.util.OSVector;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.Enumeration;
public class DumpReload {
static public void main(String argv[]) throws Exception {
if (argv.length >= 2) {
if (argv[0].equalsIgnoreCase("create")) {
createDatabase(argv[1]);
} else if (argv[0].equalsIgnoreCase("dump")) {
dumpDatabase(argv[1], argv[2]);
} else if (argv[0].equalsIgnoreCase("reload")) {
reloadDatabase(argv[1], argv[2]);
} else {
usage();
}
} else {
usage();
}
}
static void usage() {
System.err.println(
"Usage: java DumpReload OPERATION ARGS...\n" +
"Operations:\n" +
" create DB\n" +
" dump FROMDB TOFILE\n" +
" reload TODB FROMFILE\n");
System.exit(1);
}
/* Create a database with 3 roots. Each root contains an
OSHashtable of OSVectors that contain some Strings. */
static void createDatabase(String dbName) throws Exception {
ObjectStore.initialize(null, null);
try {
Database.open(dbName, ObjectStore.UPDATE).destroy();
} catch (DatabaseNotFoundException DNFE) {
}
Database db = Database.create(dbName, 0644);
Transaction t = Transaction.begin(ObjectStore.UPDATE);
for (int i = 0; i < 3; i++) {
OSHashtable ht = new OSHashtable();
for (int j = 0; j < 5; j++) {
OSVector vec = new OSVector(5);
for (int k = 0; k < 5; k++)
vec.addElement(new LinkedList(i));
ht.put(new Integer(j), vec);
}
db.createRoot("Root" + Integer.toString(i), ht);
}
t.commit();
db.close();
}
static void dumpDatabase(String dbName, String dumpName)
throws Exception {
ObjectStore.initialize(null, null);
Database db = Database.open(
dbName, ObjectStore.READONLY);
FileOutputStream fos = new FileOutputStream(dumpName);
ObjectOutputStream out = new ObjectOutputStream(fos);
Transaction t = Transaction.begin(ObjectStore.READONLY);
/* Count the roots and write out the count. */
Enumeration roots = db.getRoots();
int nRoots = 0;
while (roots.hasMoreElements()) {
String rootName= (String) roots.nextElement();
/* Skip internal OSJI header */
if (!rootName.equals("_DMA_Database_header")) nRoots++;
}
out.writeObject(new Integer(nRoots));
/* Rescan and write out the data.
The deepFetch() call is necessary because it obtains the
contents of all objects that are reachable from root,
and makes them available for serialization. */
roots = db.getRoots();
while (roots.hasMoreElements()) {
String rootName = (String) roots.nextElement();
if (!rootName.equals("_DMA_Database_header")) {
out.writeObject(rootName);
Object root = db.getRoot(rootName);
ObjectStore.deepFetch(root);
out.writeObject(root);
}
t.commit();
out.close();
}
static void reloadDatabase(String dbName, String dumpName)
throws Exception {
ObjectStore.initialize(null, null);
try {
Database.open(
dbName, ObjectStore.OPEN_UPDATE).destroy();
} catch (DatabaseNotFoundException DNFE) {
}
Database db = Database.create(dbName, 0644);
FileInputStream fis = new FileInputStream(dumpName);
ObjectInputStream in = new ObjectInputStream(fis);
Transaction t = Transaction.begin(ObjectStore.UPDATE);
int nRoots = ((Integer) in.readObject()).intValue();
while (nRoots-- > 0) {
String rootName = (String) in.readObject();
Object rootValue = in.readObject();
System.out.println("Creating " + rootName + " " + rootValue);
db.createRoot(rootName, rootValue);
}
t.commit();
db.close();
}
static
class LinkedList implements java.io.Serializable {
private int value;
private LinkedList next;
private LinkedList prev;
//private Object newField;
static final long serialVersionUID = -5286408624542393371L;
LinkedList(int value) {
this.value = value;
this.next = null;
this.prev = null;
}
}
}
To destroy a database, call the destroy() method on the Database subclass instance, for example:
db.destroy();The database must be open-for-update and a transaction cannot be in progress.
When you destroy a database, all persistent objects that belong to that database become stale.
db.isOpen();This expression returns true if the database is open. It returns false if the database is closed or if it was destroyed. To determine whether false indicates a closed or destroyed database, try to open the database.
public int getOpenMode()This method returns one of the following constants:
void checkUpdate(Database db) {
if (db.getOpenMode() != ObjectStore.UPDATE)
throw new Error("The database must be open for update.");
}
String myString = db.getPath();
db = Database.open("myDb.odb", ObjectStore.READONLY);
Transaction tr = Transaction.begin(ObjectStore.READONLY);
long dbSize = db.getSizeInBytes();
This method does not necessarily return the exact number of bytes that the database uses. The value returned might be the result of your operating system's rounding up to a block size. You should be aware of how your operating system handles operations such as these.
public Session Placement.getSession()
Information about the osjshowdb utility is in osjshowdb: Displaying Information About a Database.
Are There Invalid References in the Database?
The osjcheckdb utility or the Database.check() method checks the references in a database. This tool scans a database and checks that there are no references to destroyed objects. The most likely cause of dangling references is an incorrectly written program. You can fix dangling references by finding the objects that contain them and overwriting the invalid references with something else, such as a null value. In addition to finding references to destroyed objects, the tool performs various consistency checks on the database.
Implementing Cross-Segment References for Optimum Performance
You can improve application performance by clustering together objects that are expected to be used together. Effective clustering both reduces the number of disk and network transfers the applications require and increases concurrency among applications. You can use a segment to store groups of objects that are accessed as a logical cluster. Procedure for Defining Cross-Segment References
To obtain the greatest benefit from cross-segment references, you must do the following:
You want to minimize the number of exported objects in each segment. A segment that contains large numbers of exported objects has more overhead for the persistent system data needed to describe the exported objects. Also, references to exported objects from within their own segments might take longer because of the increased size of the system data.
Exporting Objects
When you export an object, whether you use migrate() or export(), ObjectStore
If the segment is empty or relatively empty, the actual overhead is small because there are few, if any, objects to check. If there are already many objects in the segment, the overhead of checking each one can be quite large.
Consequently, it is preferable to use the ObjectStore.migrate() method and specify true for the export argument when you store the object in the database. This also ensures that you are storing the object in the intended segment.
Suppose you forget to export a particular object when you store it in the segment. You can fix this by calling the ObjectStore.export() method on the object. However, by the time you recognize the need to export an object, there might already be many objects in the segment. The overhead for exporting the object can be quite large.
With the exception of ObjectStore collection objects, you cannot export peer objects. If you try to export a peer object that is not an ObjectStore collection object, ObjectStore throws ObjectException.
The overhead of having many exported objects in a segment comes from having many entries in the export table. Access to an exported object is through the export table. Having many exported objects is less efficient than having clustered objects because access to the exported objects requires an indirect lookup through the export table. While the lookup is implemented with a highly-tuned hashing mechanism, the overhead for maintaining the export table increases as it grows. Finally, if the exported objects are very volatile, the database locking mechanism can result in additional wait time for users who are creating or accessing exported objects.
For these reasons, it is desirable to design your application so that only a relatively small number of nonvolatile objects must be exported. The figure below shows the optimum way to set up cross-segment references.
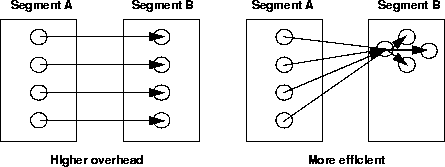
In a transaction, if you create a situation in which an object is referred to by objects in more than one segment, and the object is not exported, ObjectStore throws ObjectNotExportedException when you try to do one of the following:
Upgrading Databases for Use with the JDK 1.2
The JDK 1.2, currently in beta testing but expected to be released soon by Sun Microsystems, computes hash codes for String types differently than the JDK 1.1. As a result, databases that depend on String hash codes force the database to only be usable from the JDK 1.1 or the JDK 1.2, but not both.
To use the upgrade tool, see osjuphsh: Upgrading String Hash Codes in Databases. To use the API, see COM.odi.Upgrade.upgradeDatabaseStringHash().
The upgrade facility also allows you to mark a database as not containing any objects that depend on String hash codes. If you mark a database in this way, you can use either the JDK 1.1 or the JDK 1.2 to access the database.
After you upgrade your database, Object Design recommends that you run the garbage collector on the database. Upgrading the database creates some garbage.
If you use the upgrade API to perform the upgrade, watch out for a problem that involves cross-database references from the upgraded database to other databases. If the database being upgraded contains references to other databases, those other databases might need to be opened during the upgrade. If they are opened, the upgrade API leaves them open when it is done. The upgrade allows the other databases to be opened regardless of whether they have been upgraded because of the limited way in which the other databases are required by the upgrade. However, if the application trys to use those database after performing the upgrade, it receives exceptions if the other database are not already upgraded.
The workaround is to ensure that you upgrade all databases you intend to use before you try to access any upgraded database.
Updated: 10/07/98 08:45:04