CSCI 5333 Data Base Management System
Chapter 18: Query Processing & Optimization
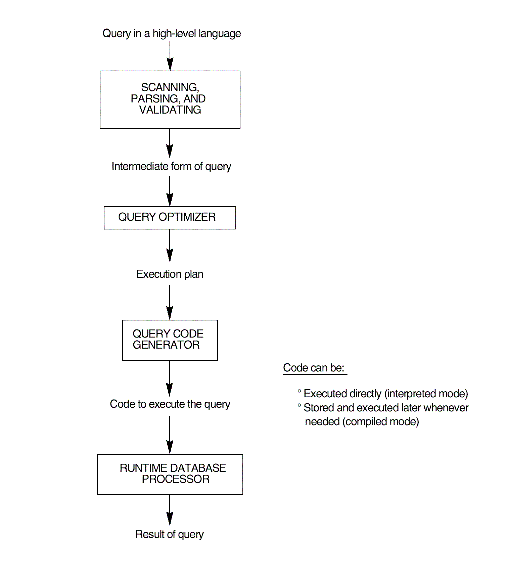
- The processing of a high-level query (See Fig. 18.1):
18.1 Translating SQL Queries into Relational Algebra
- Typically, SQL queries are decomposed into query blocks
, which form the basic units that can be translated into the algebraic operators
and optimized.
- An SQL query block is first translated into an equivalent extended
relational algebra expression—represented as a query tree data structure—that
is then optimized.
- A query block contains a single SELECT-FROM-WHERE expression,
as well as GROUP BY and HAVING clauses if these are part of the block.
- Nested queries within a query are identified as separate query
blocks.
Ø
Go to the
Index
18.2 Basic Algorithms for Executing Query Operations
- An RDBMS must include algorithms for implementing the different
types of relational operations (as well as other types of operations) that
can appear in a query execution strategy.
- An algorithm may apply only to particular storage structures
and access paths; if so, it can only be used if the files involved in the
operation include these access paths.
- External sorting refers to sorting algorithms that are
suitable for large files of records stored on disk that do not fit entirely
in main memory, such as most database files.
- The typical external sorting algorithm uses a sort-merge
strategy, which starts by sorting small subfiles—called runs—of the main
file and then merges the sorted runs, creating larger sorted subfiles that
are merged in turn.
- See Figure 18.2 (p.590) for the sort-merge algorithm
for external sorting.
- Exercise: Trace the algorithm using the following parameters:
- b (number of blocks in the file) = 15
- Suppose the blocks in the file are represented by a single
letter and the letters also serve as the primary index of the blocks:
C M A Z L T Q D B X H I F P Y
- nB (number of blocks the buffer may
hold) = 4
- Question: How many subfiles would be written at
the end of the sort phase?
- Question: How many subfiles would be written during
the first merge phase?
- Question: How many merge phases are there given
the sample data?
- Question: What is the number of block accesses?
Verify the formula in the book (p.590).
- Search algorithms for selecting records from a file are
also known as file scans.
- If the search algorithm involves the use of an index,
the index search is called an index scan.
- Exercise: Examine the first six algorithms (S1
through S6) presented on p.p. 591-592 and identify the respective prerequisites
of each of the algorithms. A prerequisite may be the type of index
or a special ordering that is needed to carry out the algorithm.
- Search methods for complex selection with a conjunctive
condition: S7, S8, S9.
- Query optimization for a SELECT operation is needed
mostly for conjunctive select conditions whenever more than one of the attributes
involved in the conditions have an access path.
- The optimizer should choose the access path that retrieves
the fewest records in the most efficient way by estimating the different
costs (see Section 18.4) and choosing the method with the least estimated
cost.
- The selectivity (s) is defined as the ratio of
the number of records (tuples) that satisfy the condition to the total number
of records (tuples) in the file (relation), and thus is a number between zero
and 1.
- Estimates of selectivities are often kept in the
DBMS catalog and are used by the optimizer.
- In general, the number of records satisfying a selection
condition with selectivity s is estimated to be | r(R) | * s.
- The smaller this estimate is, the higher the desirability
of using that condition first to retrieve records.
- Question: Do you agree at the above statement?
Justify your answer.
- Compared to a conjunctive selection condition, a disjunctive
condition (where simple conditions are connected by the
OR logical connective rather than by AND) is much harder
to process and optimize.
- Exercise: Explain why the above statement is true.
- 18.2.3 Implementing the JOIN Operation
- Methods for implementing Joins:
- J1. Nested-loop join (brute force)
- J2. Single-loop join (using an access structure
to retrieve the matching records)
- J3. Sort–merge join
- J4. Hash-join
- Exercise: Suppose, in a two-way join, the joining
attributes are both primary keys of the two relations. Modify the sort-merge
join algorithm in Figure 18.3(a) to take advantage of this fact.
- Exercise: Examine each of the above methods
and estimate the respective disk block accesses. What kind of parameters
would you need in order to perform the estimate?
- Effects of Buffer Space on Join Performance:
pp.597.
Let us consider the nested-loop approach
(J1) and the operation OP6.
Assume that the number of buffers available in main memory for implementing
the join is nB = 7 blocks (buffers).
Assume that the DEPARTMENT file consists of r
D = 50 records stored in bD = 10
disk blocks.
Assume that the EMPLOYEE file consists of r
E = 6000 records stored in bE = 2000
disk blocks.
- Question: How should the buffers be
used? Why does nB - 2 blocks need to be read into
the memory buffers from the file whose records are used for the outer loop?
Why not nB?
- Question: Which of the two files, DEPARTMENT
versus EMPLOYEE, should be chosen for the outer loop?
- It is advantageous to use the file with
fewer blocks as the outer-loop file in the nested-loop join.
- Effects of Join Selection Factor on Join
Performance: pp.598.
- The percentage of records in a file that will
be joined with records in the other file is called the join selection factor
of a file with respect to an equijoin condition with another file.
- The join selection factor affects the performance
of a join, particularly the single-loop method J2.
Let us consider the single-loop
method (J2) and the operation OP7.
Assume that the number of buffers available in main memory for implementing
the join is nB = 7 blocks (buffers).
Assume that the DEPARTMENT file consists of r
D = 50 records stored in bD = 10
disk blocks.
Assume that the EMPLOYEE file consists of r
E = 6000 records stored in bE = 2000
disk blocks.
Suppose that secondary indexes exist on both the attributes SSN of EMPLOYEE
and MGRSSN of DEPARTMENT, with the number of index levels X
SSN = 4 and XMGRSSN = 2, respectively.
- Question: What is the join selection
factor of the EMPLOYEE file with respect to an equijoin condition with the
DEPARTMENT file?
- Question: What is the join selection
factor of the DEPARTMENT file with respect to an equijoin condition with the EMPLOYEE
file?
- Question: Explain why 1, as in
XSSN + 1 and XMGRSSN +
1, is added into the formuli for the estimates of block accesses?
- For method J2, either the smaller file
or the file that has a match for every record (that is, the file with the
high join selection factor) should be used in the (outer) join loop.
- The sort-merge join J3 is quite efficient
if both files are already sorted by their join attribute.
- Exercise: Read the last paragraph
on page 598 and determine how the cost of a sort-merge join would be estimated,
based on whether the above condition is true.
- The hash-join method J4 is also
quite efficient. In this case only a single pass is made through each file,
whether or not the files are ordered.
- If the hash table for the smaller of the
two files can be kept entirely in main memory after hashing (partitioning)
on its join attribute, the implementation is straightforward.
- If, however, parts of the hash file must
be stored on disk, the method becomes more complex, and a number of variations
to improve the efficiency have been proposed.
- 18.2.4 Implementing PROJECT and Set Operations
- A PROJECT operation is straightforward
to implement if <attribute list> includes a key of relation R, because
in this case the result of the operation will have the same number of tuples
as R.
- If <attribute list> does not include
a key of R, duplicate tuples must be eliminated, when the keyword DISTINCT
is included in the SELECT query. This is usually done by sorting the result
of the operation and then eliminating duplicate tuples, which appear consecutively
after sorting. A sketch of the algorithm is given in Figure 18.03(b).
- Set operations—UNION, INTERSECTION,
SET DIFFERENCE, and CARTESIAN PRODUCT—are sometimes expensive to implement.
In particular, the CARTESIAN PRODUCT operation R x S is quite expensive.
- It is important to avoid the CARTESIAN
PRODUCT operation and to substitute other equivalent operations during query
optimization.
- The other three set operations—UNION,
INTERSECTION, and SET DIFFERENCE (Note 15)—apply only to union-compatible
relations, which have the same number of attributes and the same attribute
domains.
- The customary way to implement these
operations is to use variations of the sort-merge technique: the two
relations are sorted on the same attributes, and, after sorting, a single
scan through each relation is sufficient to produce the result.
- 18.2.7 Combining Operations Using Pipelining
- A query specified in SQL will typically
be translated into a relational algebra expression that is a sequence of relational
operations. If we execute a single operation at a time, we must generate
temporary files on disk to hold the results of these temporary operations,
creating excessive overhead.
- To reduce the number of temporary files,
it is common to generate query execution code that correspond to algorithms
for combinations of operations in a query.
- An example of pipelining (or
stream-based processing):
For example, rather than being implemented
separately, a JOIN can be combined with two SELECT operations on the input
files and a final PROJECT operation on the resulting file; all this is implemented
by one algorithm with two input files and a single output file. Rather than
creating four temporary files, we apply the algorithm directly and get just
one result file.
Ø
Go to the
Index
|
 Main Page
Main Page
Biography
Teaching
Research
Services
Other Links
Last updated:
4/02
|