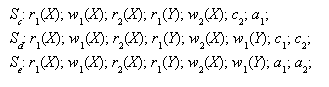CSCI 5333 Data Base Management System
Chapter 19: Transaction Processing
- Transaction processing systems are systems with large
databases and hundreds of concurrent users that are executing database transactions.
- Requirements: high availability and fast response time
for hundreds of concurrent users.
- A transaction represents a logical unit of database
processing that must be completed in its entirety to ensure correctness.
- The concurrency control problem occurs when multiple
transactions submitted by various users interfere with one another in a way
that produces incorrect results
- Recoverability: The ability for a DBMS to recover, from
a transaction failure, to a database state which was consistent before the
transaction was applied.
19.1 Introduction to Transaction Processing
- Multiprogramming allows the
computer to execute multiple processes at the same time.
- Interleaved concurrent execution of processes on a
single-processor computer.
- If the computer system has multiple hardware processors (CPUs),
parallel processing of multiple processes is possible.
- Figure 19.1: Interleaved versus parallel processing
of concurrent transactions.
- A transaction is a logical unit of database processing
that includes one or more database access operations—these can include insertion,
deletion, modification, or retrieval operations.
- A simplified database model: A database can be represented
as a collection of named data items. The size of a data item
is called its granularity.
- Using this simplified database model, the basic database
access operations that a transaction can include are as follows:
- read_item(X): Reads a database item named X into
a program variable. To simplify our notation, we assume that the program
variable is also named X.
- write_item(X): Writes the value of program variable
X into the database item named X.
- Executing a read_item(X) command includes the
following steps:
- Find the address of the disk block that contains item
X.
- Copy that disk block into a buffer in main memory (if
that disk block is not already in some main memory buffer).
- Copy item X from the buffer to the program variable named
X.
- Executing a write_item(X) command includes
the following steps:
- Find the address of the disk block that contains item
X.
- Copy that disk block into a buffer in main memory (if
that disk block is not already in some main memory buffer).
- Copy item X from the program variable named X into its
correct location in the buffer.
- Store the updated block from the buffer back to disk
(either immediately or at some later point in time).
- The read-set of a transaction is the set of all items
that the transaction reads, and the write-set is the set of all items
that the transaction writes. See Fig. 19.2 for examples.
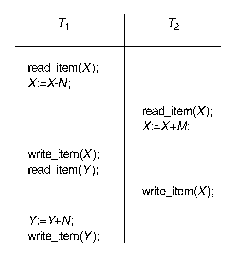
- 19.1.3 Why Concurrency Control Is Needed
- Sample concurrent transactions: T1 and T2 (See page 632)
This problem occurs when two transactions that access
the same database items have their operations interleaved in a way that
makes the update operation of one of the transactions lost
.
Example: See Figure 19.3(a), p.634.
Question: Which operation is lost?
Exercise: Reschedule the operations to fix the problem.
- The Temporary Update (or Dirty Read)
Problem
This problem occurs when one transaction updates
a database item and then the transaction fails for some reason. The
updated item is accessed by another transaction before it is changed back
to its original value.
Example: Figure 19.3(b).
- The Incorrect Summary Problem
If one transaction is calculating an aggregate
summary function on a number of records while other transactions are updating
some of these records, the aggregate function may calculate some values
before they are updated and others after they are updated.
Example: Fig. 19.3(c), p.635.
- The Unrepeatable Read Problem
When a transaction T reads an item
twice and the item is changed by another transaction T' between the two reads;
hence, T receives different values for its two reads of the same item.
Exercise: Demonstrate the
above problem by writing down two interleaved transactions. See Fig.
19.3 for examples.
- The All-or-None principle:
Whenever a transaction is submitted to a DBMS for execution, the system
is responsible for making sure that either (1) all the operations in the transaction
are completed successfully and their effect is recorded permanently in the
database, or (2) the transaction has no effect whatsoever on the database
or on any other transactions.
There are different types of
transaction failures (p.636). Whenever a failure occurs, the system
must keep sufficient information to recover from the failure.
19.2 Transaction
and System Concepts
- The
recovery manager keeps track
of the following operations:
- BEGIN_TRANSACTION
- READ or WRITE
- END_TRANSACTION
- COMMIT_TRANSACTION: This
signals a successful end of the transaction so that any changes (updates)
executed by the transaction can be safely committed to the database and
will not be undone.
- ROLLBACK (or ABORT): This
signals that the transaction has ended unsuccessfully, so that any changes
or effects that the transaction may have applied to the database must be undone.
-
Transition states of a transaction
: Fig. 19.4 (p.638)
- Exercise: List five possible
"lives" of a transaction, by clearly identifying the states and the respective
events that trigger the transition.
- A system log is a disk
file that keeps track of all transaction operations that affect the values
of database items.
- The information in the system
log may be needed to permit recovery from transaction failures.
- [start_transaction, T]
- [write_item, T,X,old_value,new_value]
- [read_item, T,X]
- [commit,T]
- [abort,T]
- A system log is mainly used
to undo the effect of WRITE
operations of a transaction.
- It may also be used to redo
some WRITE operations. How?
- A transaction T reaches its
commit point when all its
operations that access the database have been executed successfully and the
effect of all the transaction operations on the database have been recorded
in the log.
- Beyond the commit point, the
transaction is said to be committed, and its effect is assumed to be
permanently recorded in
the database. The transaction then writes a commit record [commit,T]
into the log.
- If a system failure occurs,
we search back in the log for all transactions T that have written a [start_transaction,T]
record into the log but have not written their [commit,T] record
yet; these transactions may have to be rolled back to undo their effect
on the database during the recovery process. Transactions that have written
their commit record in the log must also have recorded all their WRITE operations
in the log, so their effect on the database can be redone from the
log records.
- Force-writing the log
file before committing a transaction:
Before a transaction reaches
its commit point, any portion of the log that has not been written to the
disk yet (for example, in the main memory buffer) must now be written to the
disk.
19.3 Desirable Properties of Transactions
- Atomicity: A transaction
is an atomic unit of processing; it is either performed in its entirety or
not performed at all.
- Consistency preservation
: A transaction is consistency preserving if its complete execution take(s)
the database from one consistent state to another.
- Isolation: A transaction
should appear as though it is being executed in isolation from other transactions.
That is, the execution of a transaction should not be interfered with by any
other transactions executing concurrently.
- Durability or
permanency: The changes applied to the database by a committed transaction
must persist in the database. These changes must not be lost because of any
failure.
- The levels of isolation
of a transaction:
- A transaction
is said to have level 0 (zero) isolation if it does not overwrite the
dirty reads of higher-level transactions.
- A level 1 (one)
isolation transaction has no lost updates.
- Level 2 isolation
has no lost updates and no dirty reads.
- Level 3 isolation
(also called true isolation) has, in addition to degree 2 properties,
repeatable reads.
Atomicity
|
The
transaction recovery subsystem of a DBMS
|
Consistency preservation
|
The
database application programmers, or
the DBMS module that enforces integrity constraints
|
Isolation
|
The
concurrency control subsystem of the DBMS
|
Durability
|
The
recovery subsystem of the DBMS
|
19.4 Schedules and Recoverability
- When transactions
are executing concurrently in an interleaved fashion, then the order of execution
of operations from the various transactions is known as a schedule
(or history).
- A schedule S of
n transactions T1, T2, ..., Tn is an
ordering of the operations of the transactions subject to the constraint
that, for each transaction
Ti that participates in S, the operations of Ti
in S must appear in the same order in which they occur in T i
.
- Sample schedules:
From Figure 19.3(a) and (b).
- Two operations in
a schedule are said to conflict if they satisfy all three of the following
conditions:
- They belong to
different transactions.
- They access the
same item X
- At least one of
the operations is a write_item(X).
- Exercise:
Based on the two sample schedules above, Sa and Sb
, list at least four operations that conflict and four operations that do
not conflict.
- A schedule S of
n transactions T1, T2, ..., Tn
is said to be a complete schedule if the following conditions hold:
- The operations
in S are exactly those operations in T1, T2, ..., T
n including a commit or abort operation as the last operation for
each transaction in the schedule.
- For any pair
of operations from the same transaction Ti, their order of appearance
in S is the same as their order of appearance in Ti.
- For any two
conflicting operations, one of the two must occur before the other in the
schedule.
- A total
order must be specified in the schedule for any pair of conflicting operations
(condition 3) and for any pair of operations from the same transaction (condition
2).
- A transaction
T reads from transaction T' in a schedule S if some item X is first written
by T' and later read by T.
- A schedule S is
recoverable
if
- no
transaction
T in S commits until all transactions T' that have written an item
that T reads have committed. Why?
- T' should not
have been aborted before T reads item X. Why?
- There should
be no transactions that write X after T' writes it and before T reads it (unless
those transactions, if any, have aborted before T reads X). Why?
- WT'(X),
..., WT"(Y), ..., RT(Y), ..., RT(X), ...
- Question:
Where in the above partial schedule can you insert the operations C
T, CT',
and CT"
without making
the schedule unrecoverable?
- Question:
Explain why the sample schedule Sa is a recoverable schedule.
- Question:
Explain why the sample schedule Sb is a recoverable schedule.
- Question:
The schedule Sa' below suffers the lost update problem.
Explain why the it is still a recoverable schedule.
- Exercise:
Examine each of the following sample schedules (c, d, e) and determine whether
it is recoverable. Justify your answers.
- In a recoverable
schedule, no committed transaction ever needs to be rolled back.
- However, it is possible
for a phenomenon known as cascading rollback (or cascading abort) to
occur, where an uncommitted transaction has to be rolled back because
it read an item from a transaction that failed. This is illustrated in schedule
Se, where transaction T2 has to be rolled back because
it read item X from T1, and T1 then aborted.
- Cascading rollback
can be quite time-consuming.
- A schedule is said
to be cascadeless, or avoid cascading rollback, if every transaction
in the schedule reads only items that were written by committed transactions.
- Exercise:
Modify schedules Sd and Se to make them cascadeless.
- A strict
schedule are composed of transactions that can neither read nor write
an item X until the last transaction that wrote X has committed (or
aborted).
- Exercise:
Compare the cascadeless and the strict schedules. Explain
their differences.
- Exercise:
Explain why schedule f below is a cascadeless but not a strict
schedule.
- A strict
schedule is both cascadeless and recoverable. A cascadeless
schedule is a recoverable schedule.
19.5 Serializability
of Schedules
- In a serial
schedule, the operations of each transaction are executed consecutively,
without any interleaved operations from other transactions. See Fig.
19.5(a) and (b).
- Formally, a schedule
S is serial if, for every transaction T participating in the schedule,
all the operations of T are executed consecutively in the schedule; otherwise,
the schedule is called nonserial.
- The problem
with serial schedules
is that they limit concurrency or interleaving of operations.
- A schedule S of
n transactions is serializable if it is equivalent to some serial schedule
of the same n transactions.
- Saying that a
nonserial
schedule S is serializable is equivalent to saying that it is correct.
- Two schedules
are called result equivalent if they produce the same final state
of the database.
- Question:
What could be
a potential problem with this approach when determining the equivalency
between two
schedules?
- Result equivalence
alone cannot be used to define equivalence of schedules.
- For two schedules
to be equivalent, the operations applied to each data item affected
by the schedules should be applied to that item in both schedules in the same
order.
- Two definitions
of equivalence of schedules are generally used: conflict equivalence
and view equivalence.
- Two schedules
are said to be conflict equivalent if the order of any two conflicting
operations is
the same in both schedules.
- A schedule
S is conflict serializable if it is conflict equivalent to some
serial schedule S´.
- Exercise:
Using the above definition, explain why schedule D of Figure 19.5(c) is
equivalent
to the serial schedule A of Figure 19.5(a).
- Exercise:
Explain why schedule C of Figure 19.5(c) is not serializable.
- Testing conflict
serializability of a schedule S:

- If there is a
cycle in the precedence graph, schedule S is not (conflict) serializable;
if there is no cycle, S is serializable.
- In the precedence
graph, an edge from Ti to Tj means that transaction T
i must come before transaction Tj in any serial schedule
that is equivalent to S, because two conflicting operations appear in the
schedule in that order.
- See Figure 19.7,
p.649, for the precedence graph for the sample schedules A, B, C, and D.
- More sample schedules
(E, F) and their respective precedence graphs: Figure 19.8, pp.650-651.
- A serializable
schedule gives
the benefits of concurrent execution without giving up any correctness.
- In practice, it
is quite difficult to test for the serializability of a schedule.
Why?
- The approach taken
in most commercial DBMSs is to design protocols (sets of rules) that — if
followed by every individual transaction or if enforced by a DBMS concurrency
control subsystem — will ensure serializability of all schedules in which
the transactions participate.
- In Chapter 20,
a number of different concurrency control protocols that guarantee serializability
are discussed.
- The most common
technique, called two-phase locking, is based on locking data items
to prevent concurrent transactions from interfering with one another, and
enforcing an additional condition that guarantees serializability. This is
used in the majority of commercial DBMSs.
- Other techniques:
timestamp ordering
, multiversion protocols, and optimistic (also called certification
or validation) protocols.
- The idea behind
view equivalence
is that, as long as each read operation of a transaction reads the
result of the same write operation in both schedules, the write
operations of
each transaction must produce the same results. The read operations
are hence said to see the same view in both schedules.
- Two schedules
S and S ´ are said to be view equivalent if the following three
conditions hold:
See p.653.
- Condition 3
ensures that the final write operation on each data item is the same in both
schedules, so the database state should be the same at the end of both schedules.
- A schedule S
is said to be view serializable if it is view equivalent to a serial
schedule.
Ø
Go to the
Index
|
 Main Page
Main Page
Biography
Teaching
Research
Services
Other Links
Last updated: 4/02
|