ObjectStore Management
Chapter 1
Overview of Managing ObjectStore
This chapter briefly describes the architecture of ObjectStore and provides an overview of management tasks. For an introduction to object-oriented database management, including concepts such as persistence, see the first several chapters of the ObjectStore C++ API User Guide.
The following topics are discussed in this chapter:
What Is ObjectStore?
ObjectStore is an object-oriented database management system. It allows you to
What Is an ObjectStore Database?
An ObjectStore database is a storage location for persistent objects.
Segments
A database contains segments, which are variable-sized regions of memory. Each segment is made up of pages. The unit of transfer from persistent storage (an ObjectStore database) to program memory can be a page, a number of pages, or a segment.
Default segment
When an application creates a database, the database automatically has a special segment, called the default segment, for storing your data. The application can be written to create additional segments if that is required. If the application does not specify a segment when storing data, ObjectStore always stores data in the default segment. Segments grow (add pages) to accommodate the data that is stored in them. The size of a segment is platform dependent. Size is limited by the available persistent address range, which is typically between 230 MB and 2 GB.
Segment location
It is not possible to specify segments at fixed locations. You specify the pathname for a database and ObjectStore determines where to locate the segments.
Number of pages
in a segment
You do not need to specify how many pages are in a segment. The default segment, and any segments that an application creates, add pages as needed to hold their data. Pages are a fixed size that depends on your operating system; 4K is a common size. When an application specifies a new segment, ObjectStore creates it on a page boundary.
Page size
Page size does not limit the size of an object that you can store. Storage of an object is independent of page size. Many objects can exist on one page. One object can span many pages.
What Kinds of Databases Are There?
You can use ObjectStore to store objects in two kinds of databases, file databases and rawfs databases.
File Databases
A file database is a native operating system file that contains an ObjectStore database. You can, with some restrictions, manipulate file databases with standard operating system commands as well as ObjectStore utilities described in this book. A file database has a standard operating system pathname.
Rawfs Databases
A rawfs database is a database that you store in an ObjectStore rawfs. A rawfs (raw file system) is a private file system managed by the ObjectStore Server. It is independent of the file system managed by the operating system.
A rawfs can contain directories, subdirectories, and databases, just like the native file system. It can include links, but each link must be to another ObjectStore rawfs. The ObjectStore Server manages everything in the rawfs; everything in the rawfs is invisible to the operating system. ObjectStore provides utilities and os_dbutil class methods for operating on databases and directories in a rawfs. An ObjectStore Server can manage one rawfs, which consists of one or more Server partitions.
Rawfs partitions
You specify each partition in the rawfs with a Partitionn statement in the Server parameter file. Each partition can be either
On AIX, Digital UNIX, SGI IRIX, and Solaris, a raw partition can be greater than two gigabytes. On HP-UX, a raw partition can be as large as four gigabytes. On Windows, a raw partition can be larger than four gigabytes.
A rawfs database can span partitions. This allows you to create a database that is larger than any single disk.
When you create a rawfs database, you specify a pathname. The Server determines where in the rawfs to store your database. Thus, the logical directory structure might not map directly to the physical placement of the databases in the partitions. For example, two rawfs databases in different ObjectStore directories might be stored in the same partition.
Rawfs database
name format
ObjectStore recognizes a rawfs database by the following format:
hostname::/database_pathname
A double colon separates the host name from the database pathname. The name of a rawfs database always starts at root; it is never relative to a working directory. Slashes always separate the levels of a rawfs database name, regardless of the platform. Case is significant. For example, the following two pathnames identify different databases:
hostess::/accounts/payable/JUNE
hostess::/accounts/payable/june
You can create a rawfs during ObjectStore installation or at any time after installation. See the chapter specific to your platform for instructions.
How Do Objects Get into a Database?
When an application allocates an object in persistent storage, it specifies the database to contain that storage. An application can create a database with a call to one of the member functions listed below. You name the database in a pathname argument to the function that creates the database.
See the ObjectStore C++ API Reference for information about these functions.
How ObjectStore Controls Storage
The Server is the ObjectStore process that primarily controls object storage. With help from the client process and the Cache Manager process, the Server can manage databases for multiple client applications. These applications can be on one or multiple hosts.
What Does the Server Do?
The ObjectStore Server is a process that controls access to ObjectStore databases on a host. This includes
The Server also manages pages of data on behalf of clients running applications.
Rawfs management
For the rawfs, if there is one on the host, the Server manages the hierarchy of directories and maintains permission modes, creation dates, owners, and groups for each entry.
Usually, a Server must be running before any ObjectStore application can access databases on the host. (A locator file allows access to databases residing on a host that is not running a Server. See Chapter 5, Using Locator Files to Set Up Server-Remote Databases, for further information.)
An application can use databases that are stored on different hosts and managed by different Servers. A Server can serve clients on any number of hosts.
Multiple Servers on a host
A host can run one Server of a given ObjectStore release. You can run two ObjectStore Servers on the same host if they are different versions of ObjectStore. For example, you can run a Release 5 and Release 4 Server on the same host. Start them on different ports and use the ports file to let clients know which one to contact. See Modifying Network Port Settings for details.
A network can have a number of Servers.
What Does the Client Application Do?
ObjectStore links the client library into each ObjectStore application. In this way, each ObjectStore application is an ObjectStore client that
Client cache
Each client has its own storage area, called the client cache or simply the cache. The cache is a local holding area for data mapped or waiting to be mapped into physical memory. When a client application needs an object stored in a database, if the page that holds the object is
then the application receives a page fault; the ObjectStore client requests the page from the Server, puts it in the cache, and continues with program execution.
To change the default size of the client cache, use the OS_CACHE_SIZE environment variable. See OS_CACHE_SIZE.
Any number of clients can run on a particular host. These clients can contact
UNIX
By default, ObjectStore places the cache file in the /tmp/ostore directory. To change the default, specify an alternate directory for the OS_CACHE_DIR environment variable. Or, set the Cache Directory parameter in $OS_ROOTDIR/etc/host_cache_manager_parameters.
Windows and OS/2
The operating system determines the location of the cache in virtual memory. You cannot change the location. The cache is not a file; it is a region of virtual memory. The necessary storage is obtained from system virtual memory, which consists of physical memory plus swap file space.
See also
Refer to the ObjectStore Technical Overview for additional information.
What Does the Cache Manager Do?
The primary function of the Cache Manager is to facilitate concurrent access to data by handling callback messages from the Server to client applications. Note that the Cache Manager never reads the cache itself. The Cache Manager coordinates access by clients to cached data.
A Cache Manager starts automatically when an ObjectStore application starts, if a Cache Manager is not already running on the host. Each host that runs an ObjectStore application must have one Cache Manager. A single Cache Manager can handle callback messages for any number of client applications running on that host.
If you are running clients from two different major releases of ObjectStore, there are two Cache Managers - one for each release. Unlike running different Servers on one host, you do not need to configure ports.
The name of the Cache Manager executable is oscmgr4.
On UNIX, the oscminit executable starts oscmgr4. Normally, you never need to invoke oscminit.
Callbacks
When a client requests permission to read a page and no other client has permission to modify that page, the Server grants read permission (read ownership). The Cache Manager is not involved.
The Cache Manager is involved in the following situations:
In these situations, the clients with permission are blocking the requesting client from obtaining permission. So the Server sends a callback message to the Cache Manager on the host of the client that has the permission.
The Server cannot send callback messages directly to the client because the client might not be listening; the client might be busy running the application. The Cache Manager determines whether the read or write permission can be released or if the client requesting permission must wait.
If you are running an ObjectStore application that uses a database that nobody else is using, there are no callback messages for that database.
For information about ownership and locks, see Callback Messages Background.
Commseg
The commseg (communications segment) is where the Cache Manager maintains information about permissions on pages and whether or not the client is actually using the page. Each client has its own commseg. For every page in the cache, there is a corresponding item in the commseg.
You can use the following environment variables to modify the default attributes of the commseg. See OS_COMMSEG_RESERVED_SIZE for details.
UNIX
By default, ObjectStore places the commseg file in the /tmp/ostore directory. You can specify an alternate directory by setting the OS_COMMSEG_DIR environment variable. Another way to change the default is to set the Commseg Directory parameter in the $OS_ROOTDIR/etc/host_cache_manager_parameters file.
Windows and OS/2
The operating system determines the location of the commseg in shared memory. The commseg is not a file; it is a region of virtual memory. The illustration that follows shows the ObjectStore processes specific to Windows and OS/2.
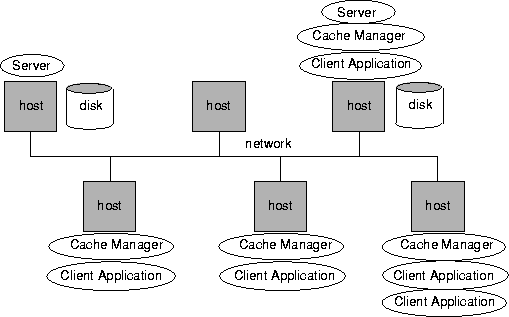
Managing Processes
ObjectStore includes three main processes that communicate with each other to manage your data:
In general, the actions you perform on ObjectStore processes are
Communication Among ObjectStore Processes
The following table summarizes the communication among the Server, client, and Cache Manager processes.
ObjectStore uses network connections to communicate among Server, client, and Cache Manager processes. The kind of network connection used depends on your platform. Normally, you do not need to modify network connections. However, if you do need to make changes, see Modifying Network Port Settings.
Starting ObjectStore Processes
Server
The chapter supporting your platform provides instructions for starting the Server on your platform. Usually, the installation procedure arranges for the Server to be started automatically when the system is booted.
When you start a Server, the Server checks for values of Server parameters you might have changed from the default and uses the modified values. If you have not modified any Server parameters, ObjectStore uses the default parameters.
The Server then makes its service available. A client can use the network connection available on its platform to connect to the Server. ObjectStore uses default network connections. To modify these connections, see Modifying Network Port Settings.
There are many Server parameters you can set to determine the behavior of the Server. Chapter 2, Server Parameters, describes each parameter. When you modify a parameter, you must shut down and restart the Server for the parameter to take effect.
Client
When a client application starts, it tries to connect to the Cache Manager on that machine. If a Cache Manager is not running, ObjectStore starts one.
Cache Manager
The Cache Manager starts automatically if one is not already running when a client application starts.
Windows NT
On Windows NT, the Server and Cache Manager normally run as NT Services. You can use the Services applet in the Control Panel to start and stop the Server and Cache Manager and to determine whether or not they start automatically when you boot the system.
Stopping ObjectStore Processes
Server
You need to shut down the Server
Use the following steps to shut down the Server:
- Use the ossvrstat utility to determine if clients are using the Server.
Along with other information, this utility displays client names if they have been set. To identify clients easily, encourage developers to use the objectstore class, set_client_name method. See ossvrstat: Displaying Server and Client Information.
- Notify clients to end their connections with the Server.
- Use the ossvrclntkill utility to end the Server's connection with any dangling clients.
Dangling clients are clients that are still attached to the Server even though they no longer exist. This can happen when a client is halted abnormally rather than being stopped in the usual manner. See ossvrclntkill: Disconnecting a Client Thread on a Server.
- Use the ossvrshtd utility to shut down the Server. See ossvrshtd: Shutting Down the Server.
To restart the Server, see the instructions in the chapter supporting your platform.
Client
Shutdown of a client is the responsibility of the application.
If necessary, you can use the ossvrclntkill utility to sever the connection between a client and the Server. This disconnects the client. See ossvrclntkill: Disconnecting a Client Thread on a Server for details.
Cache Manager
Before you shut down the Cache Manager, notify clients that you are shutting it down and then use the oscmstat utility to confirm that there are no active clients. See oscmstat: Displaying Cache Manager Status. Use the oscmshtd utility to shut down the Cache Manager. See oscmshtd: Shutting Down the Cache Manager for details. The next client process that starts automatically starts the Cache Manager.
Obtaining Process Status Information
When an ObjectStore daemon process sends output to stdout or stderr, ObjectStore routes the output to a corresponding file. These files have different names on different platforms. See Finding Files Containing ObjectStore Messages in the chapter corresponding to your platform.
ObjectStore daemons seldom send messages to these files except under certain unusual error conditions. In these cases, this information can be helpful in understanding and resolving an error. When you report to Object Design a problem that might involve one of these daemons, find such a file if it exists and provide the contents.
Meters
The ossvrstat utility displays information from a Server. For example:
This utility provides these meters and many more for several periods of time, such as the last hour and the last minute. See ossvrstat: Displaying Server and Client Information.
Use the oscmstat utility to obtain information about the Cache Manager, client cache files, and commseg files. See oscmstat: Displaying Cache Manager Status.
Debugging Cache Manager
Use the following command line to start the Cache Manager in debug mode:
oscmgr4 0 debug-level
For debug-level, specify an integer from 0 through 50. The higher the number, the more information ObjectStore displays about Cache Manager activity.
Pinging
If you are having any problems with a Server, the first thing to do is run ossvrping to see if the Server is running. See ossvrping: Determining If a Server Is Running.
Monitoring the Server
You can use the ossvrdebug command to set the debug trace level for the Server. See ossvrdebug: Setting a Server Debug Trace Level for more information.
To enable the ossvrdebug command, type ossvrdebug -d 5. To disable the command type ossvrdebug -d 0.
You can also run the Server in debug mode to obtain information about exactly what is happening. ObjectStore displays messages about process communication that show where the problems are, if there are any.
To run the Server in debug mode, you must shut down and restart the Server with the debug option. See the chapter supporting your platform for specific details. When you no longer need the debug output, shut down the Server and restart it without the debug option.
Debug mode slows down the Server but does not affect clients. Use debug mode only when you are experiencing a problem.
Description of the Server Transaction Log
Each Server keeps a transaction log, which is also called a log file. The most important function of the transaction log is to prevent database corruption in case of failure. The log contains modified pages of data and records about modified pages of data.
Log file
The log file stores database modifications until they are propagated to the database. The log does not have a consistent size. It can grow to contain as much data as is written to it. You can use the ossvrstat utility to obtain the size of the log. This is described more fully on ossvrstat: Displaying Server and Client Information.
Location
By default, the Server places its log file in the rawfs. If there is no rawfs, you must use the Log File Server parameter to specify a pathname for the transaction log. See Log File. You cannot place the log file in a raw partition. Server performance is always better when the log is in the rawfs rather than in a native file.
When the log is in the rawfs, it is not visible to you. Its size is limited by the size of the rawfs. The log can span partitions.
When the log is in the native file system, its size is limited by the file partition size. You should place the log file where it can never be accidentally deleted by users. Deleting the log file can cause database corruption.
Transactions, commits, and the log
When a transaction modifies databases, either all or none of the modifications are made, depending on whether ObjectStore commits or aborts the transaction. This is true even if the Server machine crashes during the transaction.
If your transaction aborts, the log entries are discarded. When your transaction commits, your program waits until the log information is safely on disk.
Log File Terms
The log file consists of two log record segments and a log data segment. The Server uses both the log record segments and the log data segment to store data.
Log record segment
The Server writes log records, such as commit records, to a log record segment. When a log record segment fills up, the Server switches to the other log record segment.
Log record buffer
The Server uses the log record buffer to form log records across sectors. Its size defines the maximum size that you can write to a log segment in one write operation. Each sector includes log header information that indicates which log blocks are valid.
When choosing the log record buffer size, you should consider both the cost of formatting data into a log record and the cost of a separate write operation.
Log data segment
As part of a commit record in the log segment, the Server writes data returned as part of a commit. But this occurs only if the total data being committed is small enough to fit in the log record buffer. If it is not, the Server writes the data to the data segment.
Propagation
The Server moves committed data from the log to databases through propagation. The information accumulated in the log is propagated from the log to the material (that is, real) database transparently in a way that does not interfere with client performance. After propagation, the space in the log that was occupied by propagated data becomes available for new entries in the log.
Sector
A sector is a 512-byte disk block (two sectors equal one kilobyte). When you run the ossvrstat utility, ObjectStore displays many statistics in number of sectors.
Log File Size
When the Server recognizes that it needs a bigger transaction log, it increases the size of the log segments according to the Log Data Segment Growth Increment and Log Record Segment Growth Increment Server parameters. See Log Data Segment Growth Increment for details.
When you run the ossvrstat utility, Current log size, in the list of Server parameters, displays the current size of the log. Usually, the log grows to a size that accommodates your application and then stops growing. There is usually no reason to monitor log size or worry about its allocation. However, if an unusual event causes the log to grow too large, there are ways to make it smaller.
If there is nothing in the log when you start the Server, the Server resets the size of the log data segment and log record segments to the sizes set by the Log Data Segment Initial Size and Log Record Segment Initial Size Server parameters. For log files in the rawfs, this means the space is free for other databases. For log files in the native file system, this reallocates internal log file space; the log file size does not change.
Shrinking the
log file
To move or shrink the log, follow the steps below.
- Set the Log Data Segment Initial Size and Log Record Segment Initial Size Server parameters to the values you want. If necessary, ensure that the correct value is specified for the Log File Server parameter.
- Ensure that no clients are using the Server.
- Run ossvrshtd to shut down the Server.
The Server clears the log before it actually shuts down.
- If you are reallocating a log in the rawfs skip to step 5. If you are reallocating a log in the native file system run the Server executable with the -ReallocateLog option.
This does not actually start the Server; it only reallocates the log. Enter
osserver -ReallocateLog
- Restart the Server. See the chapter discussing your operating system for details.
Another way to shrink the size of the log file is to reinitialize the Server. See the chapter supporting your platform for specific information.
Warning: Never use -ReallocateLog if the Server is in an inconsistent state. Call the ObjectStore Support group for assistance.
Managing Computer Resources
The computer resources you must manage are your CPUs, memory, disk space, and network.
CPUs
Consider the speed of your CPUs. You can run computation-intensive applications on your fastest machines, or you can distribute intensive applications evenly among network hosts. You can also combine these approaches.
Memory
ObjectStore uses several kinds of memory. Managing Memory is devoted to effective memory management.
Disk space
and network
Network communications and disk input/output are often the most constraining elements of your installation. Configure your system to minimize network and disk activities. Ensure that applications are designed to minimize this activity. Also, you probably want most of your disks, especially your fastest disks, on the Server.
It is impossible to predict how much disk space you need for a client application because it is dependent on the application. However, here are some ways that an ObjectStore application uses disk space:
The following table shows how heavily ObjectStore uses resources.
Managing Memory
To manage the memory that an ObjectStore application uses, you need to understand the concept of address space.
What Is Address Space?
ObjectStore transfers an application's data to virtual memory. Data stored in virtual memory can, at any particular time, reside in
An application's virtual memory contains both
Address space is a range of virtual memory addresses. For most 32-bit computers, the address space is slightly less than 232 bytes. (The platform's virtual memory system might reserve or might not implement a portion of the 232 range.) For 64-bit computers, the address space is substantially larger.
Each client process has its own address space. Address space is distinct from virtual memory in that
What Are the Pieces of Address Space? How Are They Shared?
A client's address space includes two kinds of addresses: persistent and transient. The data itself can be in one of three locations in physical memory or backing store. These are described in detail in this section.
Kinds of addresses
Address space includes
Just as each client has its own address space, it follows that each client has its own persistent address space, called the persistent storage region. There are two environment variables that control the size and address range of the persistent storage region. OS_AS_SIZE and OS_AS_START have different default values on different platforms. For example, the persistent storage region on a SPARCstation 10 running Solaris 2 is typically 400 MB. See OS_AS_SIZE and OS_AS_START for specific details.
Each client also has its own transient address space.
Locations for data
An application's data is stored in virtual memory. This means that data is in one of the following:
Physical memory is shared by all applications running on that machine. A typical amount of physical memory for a machine is 16 to 256 MB.
When a page of data needs to be brought into physical memory, the operating system often needs to make room by removing some other page. When the operating system removes a page from physical memory, it places the page on disk in the appropriate backing store.
If the page contains persistent data, the operating system pages it to the client cache. Each client has its own cache.
If the page contains transient data, the operating system pages it to swap space. Swap space is a disk file or disk partition that is shared by all applications running on the host.
Virtual memory
Remember that data in an application's address space is always in virtual memory. It does not matter whether the data has a persistent address or a transient address. It also does not matter whether the data is in physical memory or backing store.
Illustration of Address Space
The following figure shows address space. The persistent storage region is near the middle of the address space. The stack allocates transient data starting at one end of the range of addresses. The heap allocates transient data starting at the other end of the range of addresses. The stack and the heap can allocate space until they reach the persistent storage region.
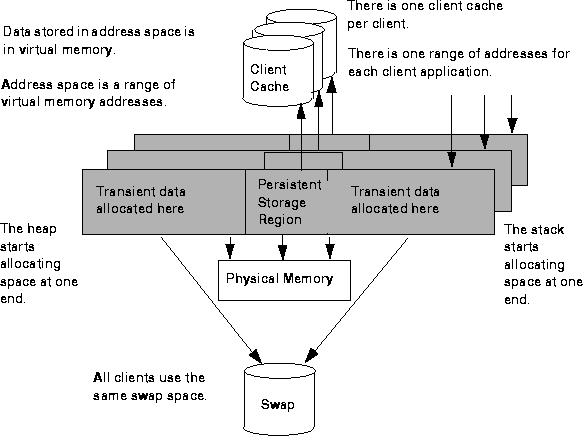
What Is the Relationship Between a Transaction and Address Space?
Address space limits the amount of data you can touch within the same top-level transaction. Address space must be reserved in order to correctly relocate data into virtual memory. As of Release 5, there are two address space assignment modes: immediate and deferred.
Under immediate assignment, the total amount of address space needed by a segment is reserved the first time any page within that segment is used in the transaction. This address space must be large enough to contain the segment itself, as well as the portions of other segments that are referred to by pointers within the segment.
Under deferred assignment, space is reserved as each page of the segment is used in the transaction, and the amount of space reserved by each page is the minimum required to correctly relocate the page into virtual memory.
The default behavior of ObjectStore in Release 5 is to use deferred assignment, since doing so prevents address space from being wasted. However, under certain circumstances, ObjectStore can detect that the pages in a segment can be brought into virtual memory without any pointer relocation. In order to ensure that the proper amount of address space is reserved without doing pointer relocation, ObjectStore uses immediate assignment for such a segment, provided that doing so does not increase the address space consumption in the transaction above half of OS_AS_SIZE.
There are several environment variables that can be used to change this behavior. See the sections on OS_IMMEDIATE_THRESH, OS_MAX_IMMEDIATE_RANGES, and OS_FORCE_DEFERRED_ASSIGNMENT for more information.
Also note that databases created prior to Release 5 or with OS_FORCE_STANDARD_PRM_FORMAT on can only use immediate assignment until they are upgraded using the osupgprm utility.
Normally, ObjectStore removes the assignments of persistent space at top-level transaction commit or abort. This allows the next top-level transaction to start with an empty persistent storage region.
However, if the application is using retain_persistent_addresses, ObjectStore does not release persistent address space until the program calls release_persistent_addresses.
Transaction commit
If a transaction commits, the client
Transaction abort
If a transaction aborts, the client
Guidelines
An application can limit the amount of address space it uses by
What Happens When Resources Are Exhausted?
Address space is large and it is unusual to exhaust it. However, lack of enough of a particular address space piece affects the application.
Persistent address space
If persistent address space is needed but not available, ObjectStore raises an exception and aborts the current transaction. This can happen when a transaction tries to assign to the persistent storage region more data than the persistent storage region can accommodate.
Physical memory
When physical memory is needed but not available, the operating system swaps pages to backing store. The application continues to run, but program execution is slower if a great deal of swapping occurs.
Client cache
When space in the client cache is needed but not available, ObjectStore attempts to migrate pages from the client cache back to the Server that supplied the data. This can impair performance. In some cases, this is impossible because the pages are wired into the cache. (ObjectStore determines which pages to wire (and unwire) into the cache. A page that is wired cannot be removed from the cache until it is unwired.) In this case, ObjectStore raises an internal error and aborts the transaction.
Swap space
If swap space is needed but not available, the operating system does one or both of the following:
How Can You Control These Resources?
Persistent address space
Increasing the size of the persistent storage region makes more address space available for a client's persistent data. This allows a transaction to assign more persistent data, which in turn might change a transaction that aborts to a transaction that commits.
The environment variables OS_AS_START and OS_AS_SIZE control the amount of persistent address space. Each application can use the default values or specify its own settings. See OS_AS_SIZE.
Physical memory
You can add physical memory to the machine to lower the reliance on backing store. This increases the performance of all applications (ObjectStore as well as non-ObjectStore) because swapping pages out of physical memory happens less often. Operating systems include tools that help you determine when an application is paging, for example, time and top in UNIX.
Client cache
Increasing the size of the cache can improve performance because it decreases the need to send pages containing persistent data back to the Server. You can control the size of the client cache with the OS_CACHE_SIZE environment variable. See OS_CACHE_SIZE.
Swap space
Adding more swap space allows you to run more or larger applications. You can add swap space by following operating system-specific procedures. Some operating systems require a system reboot to accomplish this, while others allow swap space to be added while the machine is running. Your operating system includes a tool for determining how much swap space is available, for example, pstat -s in UNIX.
Increasing the size of the client cache or adding swap space provides more potential virtual memory for the client's data.
How Much Memory Is Needed?
How much memory your application needs depends entirely on the application. Work with the application developers to understand the application's data structures and data access patterns. Start by using the default settings for the variables that control address space. Use test runs of the application to refine memory allocation.
Difference Between Assigning and Mapping an Address
When considering how a client uses address space, it is important to understand the difference between assigning an address and mapping an address.
When ObjectStore assigns an address to a page, it has determined where to put the page if the client needs it. The data on the page is not available to the client. Assigning an address reserves the address so that it cannot be assigned to another page. ObjectStore assigns address space in units of 64 KB, regardless of the page size on the platform.
When ObjectStore maps a page to an address, it means that the page is available to the client. The client can now use the data on that page.
Summary of the Kinds of Memory an ObjectStore Application Uses
An ObjectStore application uses three kinds of memory:
Persistent memory is not a limitation on how much persistent data an application can have. It is just the place where the ObjectStore client manipulates persistent data for a transaction. Persistent memory is a subset of virtual memory.
Managing the Rawfs
The chapter for your operating system includes information for creating a rawfs. The advantages of a rawfs are that it
Advantages
Security
Disadvantages
The disadvantages of a rawfs are that it
Performance
Performance varies depending on the type of database. The following lists the database types in order of performance, starting with the best:
- Rawfs database stored in a raw partition
- File database
- Rawfs database stored in a file partition
OS_DIRMAN_HOST
The OS_DIRMAN_HOST environment variable specifies a rawfs host name that ObjectStore places at the beginning of every pathname that does not already begin with the host:: rawfs prefix. This variable provides a convenient way to toggle between rawfs and native file systems. See OS_DIRMAN_HOST.
Utilities for Managing the Rawfs
ObjectStore provides the following utilities for managing the rawfs. There are many other utilities that you can use on the rawfs and on rawfs databases, but these are exclusively for operating on the rawfs.
Notes for Working with Rawfs Databases
Wildcards
ObjectStore utilities that operate on rawfs directories and databases can perform wildcard processing. The wildcards you can use are described below. For example, to list all databases in the sax directory that start with charlie, you enter the following on Server oscar:
osls oscar::/sax/charlie*
UNIX note
On UNIX systems, you must precede the wildcard with a back slash (\) or enclose the pathname with the wildcard in quotation marks (" "). This prevents the shell from interpreting the wildcard as a shell wildcard.
Reconfiguring the Rawfs
To reconfigure a rawfs, you must wipe out the existing rawfs.
See the chapter in this book discussing your platform. In that chapter are specific instructions for creating a rawfs and starting the Server on your platform. If you decide to reconfigure the rawfs, use that information with these general instructions.
Motivation
You might want to reconfigure a rawfs because you want to
Follow these instructions:
Procedure
- Confirm that you are on the machine you want to reinitialize and that your environment variables (OS_ROOTDIR and OS_DIRMAN_HOST) reflect this. You must be careful not to delete another rawfs accidentally.
- Use the ossvrstat utility to confirm that no users are changing any databases in the rawfs. The rawfs databases are backed up for the last time during this procedure.
- Use the ossvrchkpt utility to move everything in the log to the relevant databases.
- Use the osbackup utility to back up the databases in your rawfs.
- Use the ossvrshtd utility to shut down the Server.
- Modify the PartitionN Server parameter specifications to reflect your new rawfs.
- Initialize the Server by specifying osserver -i. This wipes out the rawfs partitions and starts the Server.
- Use the osrestore utility (or oscp, if you used it when saving the database) to restore any needed databases.
Planning Your Configuration
This section provides information relevant to planning your configuration.
Mixing Network Protocols
You can mix network protocols among your Servers and clients. You can configure a Server to offer its services on as many types of networks as ObjectStore supports on that platform. Clients use the first available network that recognizes the name of the Server host.
For example, an OS/2 client running APPC and a UNIX client running TCP/IP can access the same Server.
However, be sure to avoid configurations that do not allow Servers to communicate with each other, as described in the next section.
All Servers in a Transaction Must Be Able to Communicate
You must ensure that when two or more ObjectStore Servers receive modified data in a single transaction, each of those Servers can communicate with each of the other Servers. If all Servers involved in such a transaction cannot communicate with each other, ObjectStore aborts the transaction with err_cannot_commit.
The exception occurs only when a two-phase commit has problems. A two-phase commit usually occurs only if multiple Servers are being written to in that transaction. If a client reads from ServerA in one transaction and writes to ServerB in the same transaction, it is not a two-phase commit and it is not necessary for ServerA and ServerB to be able to communicate across a common network.
Running an Application from a CDROM
You can place an ObjectStore application on a CDROM and run the application from the CDROM. You can access read-only databases on the CDROM. To do this, you must allocate a Server log on a local writable disk. The Server itself (the executable files that make up the Server) can reside on the CDROM.
You should validate the schemas before you place an application and/or database on a CDROM. In other words, run the application on the database in question (in update mode) and then put the application and/or database on the CDROM. This validates the schemas and sets the appropriate cache state in the databases. The result is improved performance because schema validation is not needed when the application opens the database on the CDROM.
See additional schema validation discussions in the ObjectStore C++ API User Guide, in Chapter 2, Persistence.
What You Need to Know About the API
Some administrative tasks require familiarity with aspects of the API.
Capacity planning
Capacity planning requires knowledge of the data structures underlying any ObjectStore classes that the application stores, such as collection, relationship, and reference classes. See the ObjectStore C++ API User Guide.
Data organization
Managing the physical organization of the data (what is stored next to what) requires knowledge of the application's creation and deletion patterns and clustering directives. For information about creation and deletion patterns, talk to the application developers. For information about clustering, see Chapter 3, Transactions, in the ObjectStore C++ API User Guide.
Indexes and contention
Managing indexes uses the API, and managing contention sometimes involves the API (for example, controlling locking granularity and lock caching). See the ObjectStore Advanced C++ API User Guide for information about indexes - Chapter 5, Queries and Indexes, and for information about controlling locking granularity and lock caching - Chapter 3, Transactions.
Managing Databases
To manage databases, you are likely to perform the following typical operations:
Additional utilities for operating on databases are documented in Chapter 4, Utilities.
Pointers and references
Database management is complicated by the fact that a database often
Data set
To perform many administrative activities, you must know the relationships among the databases so you can identify the data set. The data set includes
If a database contains no external pointers or references and is not pointed to or referenced by any other database, then it alone is the data set. The application developer is often the best source for this information. If the developer is not available, you can iteratively use the ossize utility to establish the data set. See ossize: Displaying Database Size.
Schema databases
When you are operating on schema databases, you do not need to identify the data set. A schema database does not have cross-database pointers and references.
Operate on the set
After you identify a data set, you can perform an administrative function on the entire set. If you rename or move an individual database in the set, use the oschangedbref utility described in oschangedbref: Changing External Database References to fix any external pointers and references.
Moving, renaming, and dumping databases
Before moving, renaming, or dumping a database, do the following:
- Run the osverifydb utility described in osverifydb: Verifying Pointers and References in a Database to confirm that there are no bad pointers or dangling references. This utility detects inconsistencies; it does not fix them.
If you are moving a database within a rawfs, verification is not necessary because the move just changes the name.
- Run the ossize utility described in ossize: Displaying Database Size to ensure that cross-database references are correctly established.
- Perform steps 1 and 2 on all databases in the data set.
- Run the ossvrchkpt utility described in ossvrchkpt: Moving Data Out of the Server Transaction Log to ensure that all data has been propagated from the log to the affected database.
Avoiding difficulties
To avoid administrative difficulties,
Server-remote databases
Databases are usually local to the Server. However, you can enable a Server to control databases that reside on a remote host. See Chapter 5, Using Locator Files to Set Up Server-Remote Databases, for details.
Overview of the Backup/Restore Facility
ObjectStore provides the following utilities to back up and restore databases without interrupting production:
These utilities back up databases you specify to a secondary storage location. The osbackup utility performs backups according to the level you specify; that is, it copies segments that have been modified since a certain date. The osarchiv utility performs snapshots of pages modified since the previous snapshot or backup. You specify the interval between snapshots.
These utilities copy data from backups and archive media to your disk. The osrestore utility primarily restores databases from sources created by the osbackup utility. The osrecovr utility primarily restores data from archive files created by osarchiv. You can specify a point in time to which you want to recover data.
These utilities provide protection from catastrophic data loss due to hardware failure, and can also be used to transport databases from one location to another. Run the utilities in the following order:
- Run the osbackup utility (described in osbackup: Backing Up Databases) according to a schedule that you determine.
- Keep the osarchiv utility active. See osarchiv: Logging Transactions Between Backups.
- Run the osrestore utility (described in osrestore: Restoring Databases from Backups) to recover data backed up by the osbackup utility.
- Run the osrecovr utility (described in osrecovr: Restoring Databases from Archive Logs) to recover data from archive logs.
On-Line Backup and Archive Logging
On-line backup is the first step in guarding against data loss, but it cannot help you recover modifications made after the backup was performed. Archive logging provides the information needed to recover modifications made after a backup. On-line backup gives you a starting point for using archive logging.
On-line backup and archive logging provide these features:
The Server transaction log is not affected by archive logging.
On-Line Restore and Recovery
The osrestore utility restores databases from a backup image, restoring either the entire backup set or selected databases within the set. Although osrestore runs with the ObjectStore Server on-line, ObjectStore applications cannot access databases that are being restored until the entire restoration process has completed.
On-line restore and recovery offer these features:
See Backup Strategies for particular suggestions about using ObjectStore's backup and restore tools in a manner that best suits your environment.
Backup Strategies
When you develop a backup strategy, you need to consider certain conditions of your database environment. The questions to think about include:
The paragraphs that follow provide suggestions and examples of methods and tools you might use, depending on your answers to the questions posed.
General Backup Practices
Object Design, Inc. recommends a nightly backup of the ObjectStore database at a minimum. The osbackup command is an on-line utility that runs as if it were an ObjectStore MVCC client. It does not cause any concurrency conflicts.

You might choose to run Microsoft's Schedule service or use the at command to automatically invoke this operation each night. You can store the backup image on tape or on disk. If you are backing up to disk, use a separate disk for the backup images. This allows reads to occur on the source disk and writes on the target disk, which produces a faster backup and protects you from a disk crash.

You can take advantage of the cron facility on UNIX systems to automatically invoke the backup operation each night.
After the backup is complete, the backup images can then be moved to tape and eventually be stored in a safe location. For determining the best backup strategy, it is important that production size databases be estimated. If the databases are not in the gigabyte range, then it is better to perform a level 0 (full backup) every night as opposed to doing additional incremental backups. The advantage is that, in the event of a failure, only a single backup image needs to be restored. The following is a sample backup strategy:
For example, if you need to restore the databases on Friday morning, then you must restore the backup images from Sunday, Wednesday, and Thursday. It is advisable to save the previous level 0 backup in another spot before starting the new level 0 backup.
osbackup command flags
Here is a sample backup command you might use:
osbackup -i bkup_rec.txt -l 0 -f full_bkup.img sample1.db sample2.db
sample3.db
Use the same incremental record file for both osbackup and osarchiv. If you do not, osarchiv starts its archiving operation with a full copy first. Make sure that you use the most recent backup and archive images.
See osbackup: Backing Up Databases for further explanation of the options for this utility.
Archive Logging
The osarchiv utility takes much smaller pictures of the database than osbackup. Object Design recommends that you always run the osarchiv utility, even during an osbackup. The advantage of this is that, in the event of a system failure during the osbackup process, no data is lost. The osarchiv utility performs snapshots of pages modified since the previous snapshot or backup. You specify the interval between snapshots. The osarchiv utility records all transaction activity for specified databases. Since the osarchiv process requires a backup image as initial input, the script responsible for this operation might choose to stop osarchiv and restart it each night after the osbackup process completes successfully. Avoid updates in the window of time following the start of osbackup and the startup of osarchiv so osarchiv does not have to dump full segments. You can move the archive file from disk to tape at this time if disk space is an issue.
osarchiv switches to the next archive file in the sequence when it encounters the maximum size allowed for an archive file. You can specify the maximum amount with the -s flag. The default maximum size is 2 megabytes. If osarchiv runs out of disk space for archive files, it notifies you and suspends activity until additional disk space is available.
The utility uses the following naming convention for archive files:
YYMMDDHH.ext, where,
If you decrease the time between snapshots, you also decrease the number of transactions recorded in each snapshot. Shorter intervals between snapshots have the effect of keeping the archive more up to date and keeping the amount of data that needs to be archived smaller. (Can this add to the recovery process?) However, since each snapshot causes information to be written to the archive file even if no data modifications are being recorded, frequent snapshots can consume space in the archive file unnecessarily. Longer intervals can reduce the amount of data being logged in cases where the same data is modified by multiple transactions. In such cases, only the most recent copy of the committed data needs to be logged.
osarchiv command flags
The following is an example of an osarchiv command:
osarchiv -a bkup_rec.txt -d archive_img -i 30 -C sample1.db
sample2.db sample3.db
Remember that the incremental record file created with osbackup is the starting point for osarchiv. In the command line example above:
- The -a flag specifies the pathname of the file that osarchiv uses to record the segment change IDs for the archive set. The osarchiv utility updates this file each time it successfully records committed changes to the archive set. This activity is known as taking a snapshot. The osarchiv archive record file is equivalent to the incremental record file for osbackup. It is usually the same file.
- The -d flag specifies the directory in which to create the archive log files. You cannot perform archive logging directly to a tape device.
- The -i flag specifies an integer that osarchiv uses as the interval between snapshots. By default, this interval is in seconds, but you can append m, h, or d to indicate minutes, hours, or days. For example, -i 60 and -i 1m both specify an interval of one minute. When interval is not 0, osarchiv takes a snapshot immediately after being initiated and then every interval n seconds (or minutes, hours, or days) thereafter. When you do not specify an interval, it defaults to 0, which means that snapshots are not automatically taken. You can take a snapshot at any time that osarchiv is active by issuing the x command. Note that the x command can only be used when running osarchiv interactively.
- The -C flag enables the interactive command-loop feature. This feature is disabled by default.
Running osarchiv interactively
While the osarchiv utility is running with the interactive mode enabled, you can execute the following commands. The utility processes the command between snapshots.
See osarchiv: Logging Transactions Between Backups for further information about the options for this utility.
Special Considerations for Large Databases
The osbackup procedure backs up approximately 4 gigabytes an hour. The backup can take much longer under certain load conditions, such as when updates are occurring on large numbers of pages while the backup is running. Contrast this time requirement with an operating system backup that averages 20 gigabytes an hour. If you have very large databases to back up, the advantage of an on-line back up with osbackup might be less important than the amount of time it takes to do the back up. You might benefit more from shutting the ObjectStore system down and backing up the file system using operating system commands, as described next.
Using a file system backup and the ObjectStore archiver
If you keep the ObjectStore's archiver running while the operating system backup is running, the database is never without a recovery mechanism. The most dependable and least time-consuming method of backing up your data is to depend on the operating system backup and the ObjectStore archiver. The sequence of activities you need to complete is summarized in the following list:
- Freeze your applications (or shut them down).
- Perform a Server checkpoint.
- Wait for the archiver to take its snapshot.
- Shut down the archiver.
- Shut down the Server.
- Run the File system backup.
- Restart the Server.
- Restart the archiver.
- Resume or restart your applications.
Steps 3 through 5, 7, and 8 are only necessary if clients might access the Server during this procedure. If you can guarantee no client access, then you need only perform steps 1, 2, 6, and 9.
The next paragraphs describe how osrestore and osrecovr work.
Recovery Options
You should use the osrestore utility to restore databases from the most recent backup images created previously by osbackup. Recover any archived images created by the osarchiv utility by using the osrecovr utility.
Using both osrestore and osrecovr
When you are restoring databases to a specific point in time, make sure you run osrestore before you run osrecovr. The following osrestore command provides an example that assumes a full backup was performed:
osrestore -f full_bkup.img
After the database has been restored, you can then restore your database to a point in time by running the osrecovr utility with a command such as
osrecovr -F archive_list.txt
C:\name\user>type archive_list.txt
archive_img\97080719.aaa
archive_img\97080719.aab
archive_img\97080720.aac
archive_img\97080720.aad
archive_img\97080720.aae
archive_img\97080720.aaf
To recover to a specific date and time, use a command such as the following:
-F archive_list.txt -D 7/8/97 -r 19:59:45
See osrestore: Restoring Databases from Backups and osrecovr: Restoring Databases from Archive Logs for further explanation of options for these utilities.
Using system backup and osrecovr
Archive image files generated in a directory (specified by the osarchiv -d flag) can be deleted or moved to tape at your discretion. In the event of a failure, you can first restore your UNIX or Windows backup files, then invoke osrecovr with the file name that contains a list of all the archived images in the directory that was specified by the -d flag.
The Dump/Load Subsystem
This subsystem provides a facility that allows ObjectStore users to dump and load databases into and from a nondatabase format.
The ObjectStore dump/load facility allows you to
The dumped ASCII file is in a compact, human-readable format. You can edit the file using an editor such as Perl, Awk, or Sed. The ASCII file (edited or unedited) is the input for the loader.
See osdump: Dumping Databases and osload: Loading Databases in Chapter 4, Utilities for more detailed information about using the dump/load facility. For advanced topics related to customization, see Chapter 8, Dump/Load Facility in the ObjectStore Advanced C++ API User Guide.
Managing Users
There are two sorts of ObjectStore users:
This explanation focuses on what is required for those running ObjectStore applications.
Running applications
To run an ObjectStore application, you need
OS_ROOTDIR
References to ObjectStore executables, libraries, and utilities require a definition for OS_ROOTDIR. OS_ROOTDIR is an environment variable that indicates the top-level directory in the file system hierarchy containing the ObjectStore release. It serves as the prefix of various directory names used in search paths.
You can set OS_ROOTDIR on each host that runs an ObjectStore Server or application. Alternatively, you can set OS_ROOTDIR in each user's environment.
OS_ROOTDIR allows you to change the location of the ObjectStore installation and allows users to switch to a different version of ObjectStore.
Application schema database
Every ObjectStore application has one application schema database that the schema generator produces when you build your application. The application schema database contains the definitions for all classes the application uses in a persistent context. An ObjectStore executable embeds the pathname of the application schema database. Therefore, you must ensure that the application schema database is available to the executable.

You can use the ossetasp utility to change the pathname of an application schema database for a particular executable, except on OS/2.
Alternatively, an application can specify its application schema database pathname when it runs by calling objectstore::set_application_schema_path().
Sharing schemas
Multiple executables can share an application schema database. Developers create the application schema database as part of the procedure for building the application. The purpose of the application schema database is to ensure that the schema for an accessed database exactly matches the schema for an executable. ObjectStore compares the application schema with the database schema during execution.
Developing applications
To develop an ObjectStore C++ application, you need to be able to run ossg, the ObjectStore schema generator. Developers use the schema generator to create the application schema database. See ObjectStore Building C++ Interface Applications.
Modifying Network Port Settings
Normally, the default settings for ports for network services are sufficient. However, you can modify them if you need to. One reason you might want to do this is if you are running two releases of ObjectStore on a machine at one time. Another reason to modify port numbers might be if your site uses a firewall to prevent unauthorized network access. You can choose to have the firewall protect the default port numbers shown below or you can select different port numbers that are protected.
Communication Methods Background
To communicate with a network daemon such as the ObjectStore Server, a client requires a host address to identify the machine, and a port to identify a particular process. ObjectStore finds host addresses by looking up the host name in a host table or similar facility. ObjectStore uses default ports, which can be overridden if necessary, as described below. On each platform, ObjectStore supports at least two ways for processes to communicate:
The following table lists the communication channels for each platform.
UNIX
On UNIX, the remote network is always TCP/IP. For the local network, ObjectStore uses sockets to communicate among Server, client, and Cache Manager processes. Sockets use predefined ports that you can modify if necessary. A port identifies a particular application on that machine. (An address identifies a particular machine.)
Windows and OS/2
On Windows and OS/2, ObjectStore uses a variety of remote networks. Each mechanism has something analogous to port addresses that you control with the ports file.
Defaults for Port Settings
For Named Pipes, NetBIOS, and NSharedMemory, the port setting modifies the default port, so you can use the same setting for all services. On the other networks, a port setting replaces the existing port setting, so you must provide unique settings for each port that you modify.
All Servers in all ObjectStore versions have the same port number. The default port settings are in the following table.
Modifying Port Settings
To modify the settings, you change entries in the file shown in the following table. After you modify the ports file, you must shut down and restart the Server and Cache Manager for the changes to take effect. When the daemons start, they detect the existence of the ports file and use the settings in the ports file.
On UNIX, Windows, and OS/2, you can also set the variable OS_PORT_FILE to the name of a file you create.
Ports File Format
Each line in the ports file specifies the port for a network service. The syntax of a line in the ports file is
net:service:version:port
Example
TCP/IP:server client:1:54432
If a ports file is not present, ObjectStore uses default settings.
UNIX domain example
UNIX:server client:1:/tmp/.ostore/objectstore_server_comm
UNIX:cache manager client:4:/tmp/.ostore/objectstore_client_cache
UNIX:cache manager server:4:/tmp/.ostore/objectstore_server_
cache
Running Two Servers on One Host
You can run two ObjectStore Servers on the same host under some circumstances. You must specify different ports in the ports file. This lets clients know which one to contact.
Different versions
Object Design recommends that you never run two Servers that are the same ObjectStore version on the same host. If you want to run two Servers on the same host, ensure that they are different ObjectStore major versions, for example, one release 4 and one release 5 version.
To set up two Servers on the same host, you only need to change the server client ports for one of the Servers. The Cache Manager ports are already different in different major versions of ObjectStore.
All Servers that a client can communicate with must have the same network port number. This means that if you run two Servers on one host, any single client can access one of those Servers but not the other. It also means that if a client accesses Servers on more than one host, you must change the Server port settings on all affected hosts.
UNIX notes
On System V Release 4 systems, such as Solaris 2 and SGI, specify a combination of TLI_LOCAL and TCP/IP statements. Note that the TLI_LOCAL domain port names exist in a separate, flat name space.
On non-System V Release 4 systems, such as AIX, Digital UNIX, and HP-UX, specify a combination of UNIX and TCP/IP statements in the ports file. The UNIX domain or local ports have names in the file system's name space.
Windows
Object Design does not support running two Servers on one host. On Windows systems, you can specify statements for NSharedMemory, TCP/IP, and NetBIOS, according to which networks you use.
OS/2
On OS/2 systems, you can specify statements for Named Pipes, TCP/IP, and NetBIOS, depending on which networks are in use.
If you do not specify port settings correctly, and you try to start a second Server or Cache Manager, the operation fails with the following error:
<err-0001-0144>There is a server for the service <sss> already running
on net <nnn>.
When Your Application Uses Notification
When an ObjectStore application uses notifications, the client automatically establishes a second network connection to the Cache Manager on the local host. The application uses this connection to receive (and acknowledge the receipt of) incoming notifications from the Cache Manager. (Outgoing notifications are sent to the Server, not the Cache Manager.)
This all happens automatically and transparently, so there is no relevant API. However, as with all network connections, you might want to control what network port is used by the connection. You can use the ports file in the usual way to control the use of network ports. The relevant information follows.
How a Client Locates the Server for a Database
How does a client determine which Server to communicate with? The answer depends on whether the database being created or opened is a file database or a rawfs database.
When Accessing a File Database
When a client tries to open or create a file database, the client has a pathname for the database. The client looks for the Server on the machine that has the disk on which the database is or will be stored. Normally, this disk is local to the machine with the Server. In other words, the database is Server local.
If the client cannot find a Server that is local to the disk, it signals an error unless there is a locator file.
A locator file allows a client to access Server-remote databases. Server-remote databases are stored on disks that are not local to an ObjectStore Server. See Chapter 5, Using Locator Files to Set Up Server-Remote Databases.
If there is a locator file, the client checks it to determine which Server to communicate with.
When Accessing a Rawfs Database
When a client tries to open or create a rawfs database, the rawfs host is specified in one of two ways:
See Rawfs Databases.
Managing ObjectStore on Multiple Platforms
When you manage a site that runs ObjectStore on a variety of platforms, there are issues to consider that do not exist when you run ObjectStore on only one platform.
Using Multiple File Systems
ObjectStore is not dependent on a particular file system. If the usual file system calls (such as open, read, write, close) work on the file, ObjectStore can successfully use them.
Translating Pathnames
You might run an ObjectStore application on both PCs and UNIX systems. UNIX uses forward slashes in pathnames. PCs use backward slashes. How does ObjectStore handle this?
Suppose you have a UNIX Server and some Windows NT and OS/2 clients.
Native pathnames
If you are using something like an NFS client to mount the UNIX file system, you use the client's native syntax. For example, on a PC where drive Q is NFS-mounted on husky:/desktop1, ObjectStore expands the file name Q:\jet\my.db into a reference to /desktop1/jet/my.db on the Server host husky.
Server-relative pathnames
If you do not use file mounting, you can use Server-relative pathnames of the form husky:/desktop/jet/my.db. ObjectStore interprets the part of the pathname that follows the colon (:) according to the syntax of the Server host, UNIX in this example.
Callback Messages Background
The Cache Manager facilitates concurrent access to data by handling callback messages from the Server to client applications. To understand how callback messages work, you need to know about ownership and locks.
Note: The terms ownership, encached page, and permit all represent the same concept - a client has permission to read or modify the page.
Read/write ownership
Read ownership exists when a client has permission to read a particular page. Write ownership exists when a client has permission to modify a particular page.
A Server grants read ownership to as many clients as request it. If one client requests write ownership, that client must wait if there are current transactions that are reading that page, or if there is a current transaction that is modifying that page.
Many clients can have read ownership at the same time. Only one client at a time can have write ownership. When a client has write ownership, no clients can have read ownership.
Clients can release ownership in the following situations:
Read/write locks
When a client actually reads or writes a page during a transaction, it places a read or write lock on that page. When a client has a lock on a page, it means that another client cannot receive write permission for that page. A client must have read or write ownership to be able to place a read or write lock on a page. The client releases the lock when the transaction commits.
Ownership and locks
It is important to recognize the difference between ownership and locks. Ownership gives the client permission to read or modify a page. A lock allows the client to actually read or modify the page.
When a client has ownership, it can place a lock on a page without communicating with the Server.
A client can have read ownership without a read lock if it previously read the page but is not reading the page in the current transaction. The same is true for write ownership and locks.
Lazy release
The client does not give up ownership on pages when the pages are no longer needed. The client keeps ownership in case data on those pages is needed again. In contrast, the client always gives up locks when a transaction commits.
The lazy release is an optimization. If no other client needs the page that your client has ownership of, then your client does not need to request ownership from the Server for that page for as long as the client is active.
Callbacks
When a client requests read ownership for a page and no other client has write ownership, the Server grants read ownership. The Cache Manager is not involved.
The Cache Manager is involved in the following situations:
In these situations, the Server sends a callback message to the Cache Manager on the host of the client that has ownership. The Cache Manager determines whether ownership can be released or the client requesting ownership must wait.
If the client with ownership
If the first client had write ownership, and the second client is requesting read ownership, the Cache Manager downgrades the ownership of the first client from write to read. Otherwise, the client loses ownership.
API for lock management
Normally, ObjectStore performs lock management. There are, however, API features that allow a client to control whether or not a client waits for a lock. When an application uses these features, ObjectStore still uses the lazy release.
For more information about ownership and locks, see Locking in Chapter 3, Transactions, of the ObjectStore C++ API User Guide.
Troubleshooting
This section provides some examples of problems you might encounter. In general, when you receive an error message you should
These steps allow you to either take a corrective action that resolves the problem or provide Object Design Technical Support with enough information to resolve it.
Server Initialization Failed
You might try to start the Server and receive this message:
Server initialization failed
Trouble accessing ObjectStore file system.
Exception message: <maint-0018-0006>
File access permission denied
The Server is not starting. The resource affected is the Server. To obtain more information, you can
Here is another message you might receive when you try to start the Server:
Server initialization failed. (orecvery.cc line 2787)
Unknown record type 127528668 at line 1266304
Failed to start ObjectStore server
Again, the Server is not starting. The resource affected is the Server and the reference to record type might indicate a problem with the log. To obtain more information, you can
It is possible that someone accidentally deleted the log or the log might not have the correct permissions.
Miscellaneous ObjectStore Error
While running a client application you might receive this message:
Miscellaneous ObjectStore error
Reached end-of-file reading initial message from cache manager
(PID=0) (err_misc)
Segmentation Fault
The resource affected is the Cache Manager. To obtain more information, you can
UNIX
If you are mounting the file system that contains the oscminit executable, be sure that you do not specify -o nosuid. When you mount the file system, -o suid is the default; you do not need to specify it. If the mount is in the fstab file, ensure that nosuid does not appear in the mount options field.
No Handler for Exception - Database Error
While trying to access a database you might receive this message:
No handler for exception:
ObjectStore internal error Database dbname has fraction length?
(err_internal)
The resource affected is the database or the client application. To obtain more information you can
No Handler for Exception - Cannot Open Application Schema
While trying to access a database you might receive this message:
No handler for exception:
Cannot open the application schema
<err-0025-0311> The application schema database db.asdb was not
found
(err_cannot_open_application_schema)
While trying to open the application schema database.
The resource affected is the database. To obtain more information, you can
When you move an application to a machine that is not running a Server, leave the application schema database on the Server host. You must then run the ossetasp utility to patch the executable so it can find its application schema database.
The application schema database must be local to a Server. The only exception to this is when you use a locator file. See Chapter 5, Using Locator Files to Set Up Server-Remote Databases.
No Handler for Exception - Invalid Address
When trying to run a client application you might receive a message like this:
No handler for exception
ObjectStore internal error
ObjectStore referenced invalid address 0x7fff0028(0)
The resource affected is the client application. To obtain more information you can
This is a case where you might not be able to figure out the problem but you can obtain enough information for Object Design Technical Support to solve the problem quickly.
Unsupported Server Protocol
If you are running a Release 5 Server and a non-Release 5 Server on the same machine, you might receive the following message when trying to run an application.
Attempt to use unsupported server protocol.
<err-0001-0006> Server elvis does not support version 4.0 clients.
(err_protocol_not_supported)
ObjectStore displays this message when a Release 5 client tries to communicate with a non-Release 5 Server. This error might occur if you did not shut down the non-Release 5 Server while you installed the Release 5 Server. Shutting down and restarting the non-Release 5 Server should correct the situation.
Cannot Commit
You must ensure that when two or more ObjectStore Servers receive modified data in a single transaction, each Server can communicate with each of the other Servers. If all Servers involved in such a transaction cannot communicate with each other, ObjectStore aborts the transaction with err_cannot_commit.
The exception occurs only when a two-phase commit has problems. A two-phase commit usually occurs only if multiple Servers are being written to in that transaction. If a client reads from ServerA in one transaction and writes to ServerB in the same transaction, it is not a two-phase commit and it is not necessary for ServerA and ServerB to be able to communicate across a common network.
AIX - Available Space But Database Does Not Grow
Your ObjectStore database does not grow past 1.073 gigabytes, even though you have available disk space. You receive the following error:
No handler for exception:
The server is out of disk space for the database or logfile
set_segment_size call to server (host "rexx")
When you check your system, you might have statistics such as the following
rexx:phawkins(678)> df .:
rexx:phawkins(679)> ls -l mydb
-rw-rw-r-- 1 phawkins sys 1073082368 Sep 26 17:26 mydb
The problem is that you are reaching the AIX operating system default limit for the root process. This limit is 2097151 blocks, or 1073741312 bytes. The exact database size that the failure occurs at varies.
To change the limit, change the file /etc/security/limits and add -1 for the root fsize limit. For example:
default:
fsize = 2097151
core = 2048
cpu = -1
data = 262144
rss = 65536
stack = 65536
root:
fsize = -1
daemon:
bin:
sys:
adm:
uucp:
guest:
Before You Call Object Design Support
When you contact Object Design Technical Support, you need to provide
Using Virtual File Systems
A virtual file system provides a user with a logical view of a file system. When you use a virtual file system, it appears as if all sources and executables reside in the current directory path, when only local modifications actually reside there. The purpose of a virtual file system is to hide the actual locations of files from users. ClearCase is an example of a virtual file system.
Opening databases
You can run ObjectStore clients and utilities in directories where ObjectStore can find all files. However, the opening of a database is always performed by the Server. In a virtual file system, the Server cannot determine where a file actually resides unless you specify the true location.
Pathnames you
can use
When you use ObjectStore with a virtual file system you must specify pathnames that would work without the virtual file system. This is usually some kind of absolute pathname.
This requirement applies to any ObjectStore database stored under a virtual file system and includes any object that the Server must access. The Server must be able to access whatever pathname is provided. This can be a virtual file system pathname if the Server is running under a virtual file system.
Running Server under virtual file system
You can run the Server under a virtual file system if there is only one view of the virtual file system and the view is shared by all users. The Server cannot recognize more than one view. In some virtual file systems, machines and users can have their own views.
Schema databases
You can maintain schema databases in a virtual file system because the schema generator embeds the absolute pathname of the schema in the database. However, when you generate schema databases, you must specify pathnames that the Server can use.
Some virtual file systems provide a way to return an absolute (nonvirtual) pathname for a given element in a virtual file system. This pathname can enable the ObjectStore Server to locate the element. It does mean the loss of the ability to use leaf names (such as eng_1.libschema in the following example) as arguments to ObjectStore utilities.
Sample error message
Here is an example of the type of message you might receive when ObjectStore cannot find a file. Notice that the file appears to be there.
> pwd
/home/clients/libschemas
> ls
test_1.libschema
eng_1.libschema
qa_1.libschema
> ossize eng_1.libschema
ossize: The database was not found
<err-0025-0351>The database
"/home/clients/libschemas/eng_1.libschema"
does not exist (err_database_not_found)
[previous] [next]
Copyright © 1997 Object Design, Inc. All rights
reserved.
Updated: 03/26/98 20:13:22