With ObjectStore, storing persistent data is a lot like storing transient data with plain C++ or C - you allocate memory and assign a value to that memory. The only difference is that if you want to store persistent data, you allocate persistent memory. What sort of memory you allocate (persistent or transient) is independent of the type of value you want to store there, so any type of value can be stored in either persistent or transient memory.
Once you have allocated persistent memory, you can use pointers to this memory in the same way you use any pointers to virtual memory. Pointers to persistent memory, in fact, always take the form of virtual memory pointers. See ObjectStore Memory Mapping Architecture for an understanding of how memory mapping works.
Prerequisites to Persistent Access
Before you access persistent memory, you must set the stage by performing a few other operations:
Databases
When you create a persistent object, you create it in a particular database. You specify the database as an argument to persistent new. Before any of this, however, you must create a database. In subsequent processes, you must open the database each time you read from or write to it. These topics are discussed in the following sections:
Additional information on segments and clustering can be found in Chapter 1, Advanced Persistence, of the ObjectStore Advanced C++ API User Guide.
Transactions
A program must, before it accesses persistent data, start a transaction. While the transaction is in progress, the program's actions can include reads and writes to persistent objects. The program can then either commit or abort the transaction at any time.
Transactions are discussed in further detail in Chapter 3, Transactions. Additional information can be found in Chapter 2, Advanced Transactions, of the ObjectStore Advanced C++ API User Guide.
Roots and Entry-Point Objects
A database root provides a way to give an object a persistent name, allowing the object to serve as an initial entry point into persistent memory. When an object has a persistent name, any process can look it up by that name to retrieve it. Once you have retrieved one object, you can retrieve any object related to it by using navigation (that is, following data member pointers), or by a query (a query selects all elements of a given collection that satisfy a specified condition - see Chapter 5, Queries and Indexes, in the ObjectStore Advanced C++ API User Guide).
Initializing ObjectStore
Any program using ObjectStore functionality (with certain exceptions, listed below) must first call the static member function objectstore::initialize().
static void initialize() ;A process can execute initialize() more than once; after the first execution, calling this function has no effect.
The following functions are exceptions to this, and must be called before objectstore::initialize():
Single-Threaded Applications
If your application does not use multiple threads, you must disable thread locking by issuing the following two calls at the beginning of the transaction:
objectstore::set_thread_locking(0) ;
os_collection::set_thread_locking(0) ;
For information on thread locking, see Threads and Thread Locking.
Fault Handler Macros for Multithreaded Applications
On the HP-UX, SGI IRIX, and Digital UNIX platforms, signal handlers are installed strictly on a per-thread basis and are not inherited across pthread_create calls. On these platforms, then, you must use the OS_ESTABLISH_FAULT_HANDLER and OS_END_FAULT_HANDLER macros at the beginning and end of any thread that performs ObjectStore operations. Note that these macros are only required for threads that use ObjectStore.
Creating Databases
You create databases with members of the class os_database. This is true for both file databases and ObjectStore rawfs databases. Creating a Database with os_database::create()
You create a database by calling the static member function os_database::create(). This function also opens a newly created database. You can call this function from either inside or outside a transaction, although, in general, it is best to create databases outside a transaction.
static os_database *create(
const char *pathname,
os_int32 mode = 0664,
os_boolean if_exists_overwrite = 0,
os_database *schema_database = 0
) ;
Note that, since os_database::create() is static, it has no this argument.
When you create file databases, the pathname consists of an operating system pathname. (This book uses UNIX-style database pathnames with slashes (/) as separators, but your operating system might use a different style of pathname.)
os_database *db1 = os_database::create( "/ken/parts1" ) ;ObjectStore takes into account local network mount points when interpreting the pathname, so the pathname can refer to a database on a foreign host. Remember that an ObjectStore Server must be running on any host containing an ObjectStore database.
If you want to refer to a file database on a foreign UNIX host for which there is no local mount point, you can use a Server host prefix, the name of the foreign host followed by a colon (:), as in oak:/foo/bar.
The requisite database pathname syntax differs for rawfs databases. See Rawfs Databases.
If you supply the pathname of a database that already exists, the exception err_database_exists is signaled at run time (but see Automatic Overwrite, below).
Database Modes
The mode argument specifies a protection mode (see the oschmod utility in ObjectStore Management). The mode defaults to 0664. The mode argument must begin with a zero (0) to indicate that it is an octal number. For example:
os_database *db1 = os_database::create("/ken/parts1", 0666) ;
os_database *db1 = os_database::create("/ken/parts1", 0666, 1);
This argument defaults to 0 (false). If no database of that name already exists, the third argument has no effect.
When you create a database, if the schema_database argument is 0, schema information is stored in the new database (which you are creating). If schema_database is nonzero, the argument is interpreted to be another, extant, database that will be used as the schema database for the newly created database. ObjectStore puts all the schema information for the new database in the specified schema database; the new database itself will have no schema information in it.
Return Value
The static member function os_database::create() returns a pointer to an object of type os_database. You use this pointer as the this argument to other nonstatic member functions of the class os_database, such as os_database::close() (the function you use to close a database). Creating Databases with os_database::open()
Typically, os_database::create() is used to create a database, but, under some circumstances, the function os_database::open() creates a database. One form of this function requires you to specify the pathname of the database you want to open; you can specify an optional argument to direct the function to create a database if a database with the specified pathname does not exist. See the description of this function in Opening Databases with os_database::open().
Destroying Databases with
You can destroy a database with the os_ database::destroy() function.
os_database::destroy()
void destroy() ;This function takes no arguments (other than the this argument), and has no return value.
os_database* db1;
. . .
db1->destroy();
If the database is open at the time of the call, destroy() closes the database before deleting it. Note that to help ensure program portability, you should call the destroy function from outside any transaction.
Data already cached in the process's client cache will continue to be accessible, but attempts to access other data will cause ObjectStore to signal err_database_not_found. Attempts to open the database will also provoke err_database_not_found. Note that performing os_database::lookup() on the destroyed database's pathname might succeed, since the instance of os_database representing the destroyed database might still be in the process's local cache.
If you call this function to destroy a database from within a transaction, be aware of the following:
Opening a Database with os_database::open()
If you want to open a previously created database, you use the function os_database::open().
static os_database *open(
const char *pathname,
os_boolean read_only = 0,
os_int32 create_mode = 0
) ;
static os_database *open(
const char *pathname,
os_boolean read_only,
os_int32 create_mode,
os_database *schema_database
) ;
void open( os_boolean read_only = 0 ) ;
The first two overloadings return a pointer to the opened database (see Return Value).
Database Pathnames
If there is no database with the specified pathname, an err_database_not_found exception is signaled. For information about pathnames for file databases, see Database Pathnames.
Rawfs databases use a somewhat different pathname syntax; see Rawfs Databases.
Opening Read-Only
The os_database::open() function has an optional argument, an os_boolean (int or long, whichever is 32 bits on your platform) that specifies whether the database is to be opened for read only. A nonzero integer indicates read only, and 0 indicates that write access is allowed. The default is
os_database *db1 = os_database::open("/ken/parts1", 1) ;
If you attempt write access to a database that has been opened for read only, an err_opened_read_only exception is signaled.
os_database* db1 = os_database::open("/ken/parts1", 0, 0664);
Multiversion Concurrency Control (MVCC)
If you want to use multiversion concurrency control (MVCC), which allows you to perform nonblocking reads of a database, you can do so with the following members of os_database:
void open_mvcc();
static os_database *open_mvcc(const char *pathname);
Multiversion Concurrency Control (MVCC) is described in Chapter 2, Advanced Transactions, of the ObjectStore Advanced C++ API User Guide.
Closing Databases with os_database::close()
You close a database by calling os_database::close().
void close() ;This makes the database's data inaccessible (assuming you have not performed nested opens - see Nested Database Opens). If the call to os_database::close() occurs inside a transaction, the database is not actually closed until the end of the outermost transaction. That is, the data remains accessible until the outermost transaction terminates.
os_database* db1;
. . .
OS_BEGIN_TXN(tx1, 0, os_transaction::update)
. . .
db1->close();
. . . /* data in db1 remains accessible */
OS_END_TXN(tx1)
/* end of transaction, so db1 data is now inaccessible */
This is because, whenever os_database::open() is performed on a database, its open count is incremented by one. In order to close a database and make it inaccessible, its open count must reach zero. Each call to os_database::close() decrements the open count by one. If the call occurs inside a transaction, it does not actually take effect until the end of the outermost transaction. That is, the open count is not decremented until the outermost transaction terminates.
#define TRUE 1
main(){
os_database* db1;
. . .
db1->open(); /* open count is 1, read/write access */
. . .
my_func(db1);
. . .
db1->close(); /* open count is 0, data inaccessible */
}
void my_func (os_database *the_db) {
the_db->open(TRUE); /* open count is 2, read-only access */
. . .
the_db->close(); /* open count is 1, read/write access */
}
os_boolean is_open() const;
os_boolean is_open_read_only() const;
os_boolean is_open_mvcc() const;
These functions return a nonzero integer for true and 0 for false. So, for example, the loop shown below repeatedly calls close() on the database db1 until its open count is zero:
os_database* db1;
. . .
while (db1->is_open())
db1->close();
static os_database *lookup(const char *pathname, create_mode) ;If the named database exists, a pointer to the database is returned, but the database remains unopened. If no such database exists and the create_mode argument is either 0 or absent, an err_database_not_found exception is signaled. If create_mode is nonzero, however, ObjectStore attempts to create the database, just as os_database::open() does (see Opening Databases with os_database::open()).
os_database:lookup() is described in the ObjectStore C++ API Reference.
Pathname Lookup
You can find the pathname of a database, given a pointer to it, by using the function os_database::get_pathname().
char *get_pathname() const ;This function returns a char*, the pathname of the database pointed to by the this argument. The char* points to an array allocated on the heap by this function, so it is your responsibility to deallocate the array when it is no longer needed.
In the prefix, host-name names the machine running the ObjectStore Server managing the desired ObjectStore directory hierarchy. The example below specifies that a newly created database named /ken/design/parts1 is to be stored in the hierarchy managed by the Server running on the host named beech.
os_database *db1=
os_database::create("beech::/ken/design/parts1");
Note that pathnames of ObjectStore directories and databases use forward slashes no matter which operating system is being used, and pathnames always begin with a slash (/).
This section describes the basic use of persistent new. More sophisticated uses of persistent new allow you to control data clustering, and perform transient allocation. See Basic Clustering.
Creating Nonarrays with Operator new()
Use the following overloadings of ::operator new() for creating scalar objects in persistent memory:
extern void * operator new (
size_t,
os_database *where,
os_typespec *typespec
) ;
extern void * operator new (
size_t,
os_segment *where,
os_typespec *typespec
) ;
extern void * operator new (
size_t,
os_object_cluster *where,
os_typespec *typespec
) ;
where specifies where in persistent storage the new object is to be stored; that is, you specify the database or, if you would like, the particular segment (object cluster) in which the new object should reside.typespec specifies the type of the object you are creating. See Using Typespecs.
os_typespec *part_type = new os_typespec("part") ;
part *a_part = new(db1, part_type) part(111) ;
In this example, the new object will be stored in the database pointed to by db1. Here, as with ordinary new, a pointer to the newly created object is returned. All memory allocated by ObjectStore new is initialized with zeros.
extern void * operator new (
size_t,
os_database *where,
os_typespec *typespec,
os_int32 how_many
) ;
extern void * operator new (
size_t,
os_segment *where,
os_typespec *typespec,
os_int32 how_many
) ;
extern void * operator new (
size_t ,
os_object_cluster *where,
os_typespec *typespec,
os_int32 how_many
) ;
how_many specifies the number of elements you want the array to have. For example:
part *some_parts = new(db1, part_type, 10) part[10];This call allocates and initializes an array of ten parts. Notice that an os_typespec for the type part is passed, not part[] or part[10]. In fact, there are no os_typespecs for array types.

Pointers to and from Persistent Memory
The persistent new operator returns a pointer to persistent memory. You use pointers to and from persistent memory in much the same way as you use pointers to and from transient memory. There are a few restrictions that apply, which are discussed in Pointer Validity.
Clustering
If an object points to an auxiliary data structure, like an associated character array, it is sometimes a good idea to allocate the object and the auxiliary structure within the same segment, or region of memory. See Basic Clustering.
Using Typespecs
Typespecs, instances of the class os_typespec, are used as arguments to persistent new to help maintain type safety when you are manipulating database roots. A typespec represents a particular type, such as char, part, or part*.
Typespecs for Fundamental Types
ObjectStore provides some special functions for retrieving typespecs for types. The first time such a function is called by a particular process, it allocates the typespec and returns a pointer to it. Subsequent calls to the function in the same process do not result in further allocation; instead, a pointer to the same os_typespec object is returned.
static os_typespec *get_char();
static os_typespec *get_short();
static os_typespec *get_int();
static os_typespec *get_long();
static os_typespec *get_float();
static os_typespec *get_double();
static os_typespec *get_long_double();
static os_typespec *get_pointer();
static os_typespec *get_signed_char();
static os_typespec *get_signed_short();
static os_typespec *get_signed_int();
static os_typespec *get_signed_long();
static os_typespec *get_unsigned_char();
static os_typespec *get_unsigned_short();
static os_typespec *get_unsigned_int();
static os_typespec *get_unsigned_long();
class employee {
public:
char *name;
employee(char* n) {
name = new(
os_database::of(this),
os_typespec::get_char(),
strlen(n)+1
) char[strlen(n)+1];
strcpy(name, n);
}
} ;
static os_typespec *get_os_typespec() ;The ObjectStore schema generator will automatically supply a body for this function, which will return a pointer to a typespec for the class.
If you cannot modify the class definition, use the os_typespec constructor.
To create an os_typespec, pass a string (the name of the type you want to create a typespec for) to the os_typespec constructor. This works for built-in types (such as int and char), for classes, and for pointer-to-class and pointer-to-built-in types. The typespec must be allocated in transient memory. Here is an example:
os_typespec *part_type = new os_typespec("part");
When you create an os_typespec, the type-name argument cannot include a space. So, if the type-name argument includes the character * (asterisk) for pointer types, the character must not be preceded by a space:
os_typespec *part_pointer_type = new os_typespec("part*");
Once you have created an os_typespec for a particular type (the type part in the example above), you can use it to create all the program's new instances of that type; there is no need to create a separate os_typespec for each call to new. Although it is legal, it would be inefficient to do so.
os_typespec part_type ("part");
for (int i=1; i<100000; i++)
new(db1, &part_type) part (i);
Do not use the following inefficient model that includes unnecessary repetition within the loop:
for (int i=1; i<100000; i++){
os_typespec part_type("part");
new(db1, &part_type) part (i);
}
Typespecs should only be allocated transiently; you should not create a typespec with persistent new.
template <class T> class PT {
. . .
void foo(os_database *db) {
/* allocate PT<T> persistently */
new(db, "PT<???>") PT<T>() ;
/* allocate type T persistently */
new(db, "???") T() ;
}
} ;
This approach does not work, however, since there is no way to know, when coding, what to fill in for ???. T cannot be used because the C++ template facility will not instantiate it properly - it is inside a string.The solution is to declare a get_os_typespec() member function for the parameterized class, as well as for each class that will serve as parameter.
class PT_parm {
public:
static os_typespec *get_os_typespec() ;
} ;
template <class T> class PT {
static os_typespec *get_os_typespec() ;
void foo(os_database *db) {
/* allocate new PT<T> persistently */
new(db, PT<T>::get_os_typespec()) PT<T>() ;
/* allocate type T persistently */
/*(assuming it is a suitable class) */
new(db, T::get_os_typespec()) T() ;
}
} ;
#include <ostore/ostore.hh>
class note {
public:
/* Public Member functions */
note(const char*, note*, int);
~note();
void display(ostream& = cout);
static os_typespec* get_os_typespec();
/* Public Data members */
char* user_text;
note* next;
int priority;
};
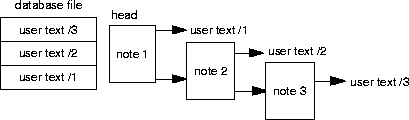
In order to establish an entry point, an os_database_root called root_head is assigned and points to the value returned from the find_root member function defined on the class os_database. The head variable is assigned to point to the value returned by the get_value function applied to root_head.Each note instance and its user text is allocated persistently, and a transaction surrounds the code that touches persistent data. The value of the database root is set to the head of the linked list.
It is important to recognize that embedding the linked list by means of note*next; is not always a reasonable practice. The use of a collection class is a better method of establishing the order of the notes. This method is explained in Chapter 5, Collections.
#include "note.hh"
extern "C" void exit(int);
extern "C" int atoi(char*);
/*Head of linked list of notes */
note* head = 0;
const int note_text_size = 100;
main(int argc, char** argv) {
if(argc!=2) {
cout << "Usage: note <database>" << endl;
exit(1);
} /* end of if */
objectstore::initialize();
char buff[note_text_size];
char buff2[note_text_size];
int note_priority;
os_database *db = os_database::open(argv[1], 0, 0644);
OS_BEGIN_TXN(t1,0,os_transaction::update {
os_database_root *root_head = db->find_root("head");
if(!root_head) root_head = db->create_root("head");
head = (note *)root_head->get_value();
/* Display existing notes */
for(note* n=head; n; n=n->next)
n->display();
/* Prompt user for a new note */
cout << "Enter a new note: " << flush;
cin.getline(buff, sizeof(buff));
/* Prompt user for a note priority */
cout << "Enter a note priority: " << flush;
cin.getline(buff2, sizeof(buff2));
note_priority = atoi(buff2);
head = new(db, note::get_os_typespec())
note(buff, head, note_priority);
root_head->set_value(head);
} /* end transaction */
OS_END_TXN(t1)
db->close();
}
The reason for the second restriction concerns ObjectStore's memory mapping architecture. Pointers to persistent memory are sometimes virtual memory addresses that are, as yet, unmapped. When dereferenced, a hardware fault occurs and ObjectStore handles the fault to retrieve the intended data. If you pass such a pointer to a non-ObjectStore process, and the process dereferences the pointer, ObjectStore will not handle the fault. (See also ObjectStore Memory Mapping Architecture.)
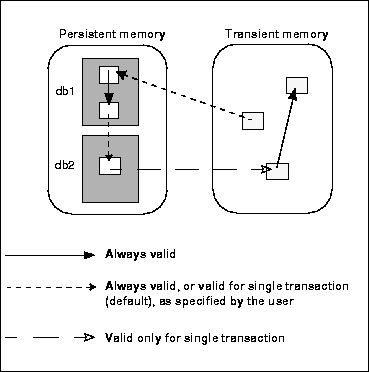
Cross-Database Pointers
To help boost the performance of certain kinds of applications, ObjectStore's default mode for new databases and segments does not permit cross-database, or external, pointers. In this mode, if a pointer to persistent memory in one database is assigned to persistent memory in a different database, that pointer is valid only until the end of the outermost transaction in which the assignment occurred.
Cross-Transaction Pointers
ObjectStore supports a mode in which transient pointers to persistent memory are invalidated at the end of each transaction. In this mode, if you assign to transient memory a pointer to persistent memory, the pointer is valid only until the end of the outermost transaction in which the assignment occurred. This can save on address space consumption and provide a performance improvement for some applications that do not need to retain such pointers across transaction boundaries.
Pointers to Transient Memory
Do not use pointers from persistent to transient memory across transaction boundaries. If a pointer to transient memory is assigned to persistent memory, that pointer is valid only until the end of the outermost transaction in which the assignment occurred. Use of access hooks
If pointers from persistent to transient memory are useful for your application (for example because some persistent objects point to data structures that you want to take one form in persistent memory and another form in transient memory), you might find ObjectStore access hooks useful. See the discussion on os_database::set_access_hooks() in the ObjectStore C++ API Reference.
Pointer Validity Summary
Basic Clustering
If an object points to an auxiliary data structure, like an associated character array, it is sometimes a good idea to allocate the object and the auxiliary structure in the same database segment. For example, if you want the constructor for the class employee to allocate a character array to hold the new employee's name, you might want to allocate the array in the same segment as the employee.
os_segment* segment_of() const;Here is how to use os_segment::of() to cluster an employee with the employee's name:
extern os_typespec *char_type;
class employee {
public:
char *name;
. . .
employee(char* n) {
name = new(os_segment::of(this),
char_type, strlen(n)+1)
char[strlen(n)+1];
strcpy(name, n);
}
};
For information on how to create segments, see Creating Segments.
Transient Allocation
Writing the constructor in this way has the added advantage that, if the employee is transiently allocated, the character array holding the name will be transiently allocated as well. This is because os_segment::of() returns a pointer to the transient segment when its argument is transient. Passing the transient segment to ObjectStore's new operator results in transient allocation. This allows you to use ObjectStore new to allocate either persistent or transient memory, depending on the run-time values of its arguments. Database Entry Points and Data Retrieval
Once you have allocated an object in persistent storage, and stored some data there, how do you retrieve it in subsequent processes? There are four possibilities:
When to Use Persistent Names
It is important to realize that you do not have to give most objects persistent names. This is because you usually retrieve objects in one of the other two ways - either by query or navigation. The only reason you need to name objects is to provide yourself with an entry point into persistent memory. Once you have retrieved an entry point object, all objects reachable from it by navigation or query will be automatically retrieved when needed. Establishing Entry Points
An object can be used as an entry point if you associate a string with it by using a root, an instance of the system-supplied class os_database_root. Each root's sole purpose is to associate an object with a name. Once the association is made, you can retrieve a pointer to the object by performing a lookup on the name using a member function of the class os_database. Creating Database Roots
Below are some examples. They show how to associate an object with a name using a root, so the object can be used as an entry point. They also show how to retrieve from the database a pointer to the object by performing a lookup on the name.
os_database *db1;
part *a_part;
os_typespec *part_type = new os_typespec("part");
. . .
a_part = new(db1, part_type) part(111);
os_database_root *a_root = db1->create_root("part_0");
a_root->set_value(a_part);
In this example, a root is created with a member of the class os_database, the function os_database::create_root(). The function returns a pointer to an instance of the class os_database_root. The this argument for the function must be the database in which the entry point is stored. If you use the transient database, an err_database_not_open exception is signaled.This function requires you to specify the name to be associated with the entry point, but the entry point itself is specified in a separate call, using the function os_database_root::set_value().
The return value of create_root() is a pointer to the new root. The root is stored in the specified database, in a special segment for database roots. create_root() copies the name you supply into this persistent memory, so you can pass a transiently allocated string.
If you pass a name to create_root() that is already associated with a root in the specified database, an err_root_exists exception is signaled.
You can get the string associated with a root with the function os_database_root::get_name(). This function returns a char*.
The pointer you supply as argument to set_value() must point to memory in the database containing the root. If it points to transient memory or memory in another database, the exception err_invalid_root_value is signaled.
Clustering of Roots
You cannot control the clustering of database roots. ObjectStore always stores the roots of each database together in a special segment. Retrieving Entry Points
Once one process within an application has created the database root and set its value (to point to the entry point), other processes (or the same process) can retrieve the entry point this way:
os_database *db1;
part *a_part;
os_database_root *a_root;
. . .
a_root = db1->find_root("part_0");
if (a_root)
a_part = (part*) (a_root->get_value());
The this argument of os_database::find_root() (db1 in this example) is a pointer to the database containing the root you want to look up. The other argument (part_0 in this example) is the root's name. If a root with that name exists in the specified database, a pointer to it is returned. If there is no such root, the function returns 0.The function os_database_root::get_value() returns a void*, a pointer to the entry point object associated with the specified root. Since the returned value is typed as void*, a cast is usually required when retrieving it. Here, the returned value is cast to part*, since the entry point is a part.
Type Safety for Database Roots
You can gain some additional type safety in your use of database roots by supplying an os_typespec* (see Using Typespecs) as the last argument to os_database_root::set_value() and os_database_root::get_value(). The typespec should designate the type of the entry point object, the object pointed to by the root's value. The first function stores the typespec in the database, and the second function signals an err_type_mismatch exception if the specified typespec does not match the stored one.
os_database *db1;
part *a_part;
os_typespec *part_type = new os_typespec("part");
. . .
a_part = new(db1, part_type) part(111);
db1->create_root("part_0")->set_value(a_part, part_type);
In this example, notice that the os_typespec* argument to set_value() and get_value() points to a typespec for part (not part*).Note that get_value() checks only that the typespec supplied to it matches the stored typespec, and does not check the type of the entry point object itself.
os_database *db1;
. . .
delete db1->find_root("part_0");
When you delete a root, the os_database_root destructor deletes the associated persistent string as well, but the associated entry point object is not deleted.Frequently the only way of retrieving an entry point object is through its associated root. So be careful to retrieve such an object before deleting its root. Then you can delete it or establish another access path to it.
Including a Class in the Application Schema
The OS_MARK_SCHEMA_TYPE() macro
To include a class in the application schema you mark it with a call to the macro OS_MARK_SCHEMA_TYPE() inside a function body. You should simply use a dummy function for this purpose (you can name the function anything you want). Example: macro use
#include <ostore/ostore.hh>
#include <ostore/coll.hh>
#include <ostore/manschem.hh>
#include "part.hh"
#include "epart.hh"
#include "mpart.hh"
void dummy() {
OS_MARK_SCHEMA_TYPE(epart);
OS_MARK_SCHEMA_TYPE(mpart);
OS_MARK_SCHEMA_TYPE(part);
}
See ObjectStore Building C++ Interface Applications for information on class templates and schema source files.If you supply the -make_reachable_classes_persistent yes flag to the schema generator (see ObjectStore Management), you do not actually need to mark every class used in a persistent context; it is sufficient to mark those classes
For applications that link with libraries that operate on persistent data, the application schema includes the schemas for the libraries. Library schemas are recorded in library schema databases (see ObjectStore Building C++ Interface Applications), and are themselves generated from schema source files.
A database's schema is determined by the schemas of the applications that access the database. An application augments the schema of a database in one of two ways: through batch schema installation or through incremental schema installation. Batch installation is the default.
Batch Database Schema Installation
With batch schema installation, whenever an application first accesses a database, each class in the application's schema that might be persistently allocated is added to the database's schema (if not already present in the database schema). Subsequent runs of the application will not have to install schema in that database, unless the application's schema changes (as evidenced by a change in date of the application schema database). Incremental Database Schema Installation
If you want you can specify, for a particular database, that schema installation should be incremental. With incremental schema installation, a class is added to a database's schema only when an instance of that class is first allocated in the database. Incremental schema installation by database
By default, each new database is in batch installation mode. You can change this by using the OS_INC_SCHEMA_INSTALLATION environment variable, described in ObjectStore Management, or by using the os_database::set_incremental_schema_installation() function. Performing this function on a database, with a nonzero 32-bit integer (true) as argument, causes the applications that subsequently open the database to install schema in an incremental fashion. The function is declared
void os_database::set_incremental_schema_installation(
os_boolean
) ;
os_boolean is a 32-bit integer type defined as int or long, depending on platform. Calling this function with 0 (false) as its argument sets the specified database's installation mode to batch.
This function also specifies the schema installation mode for databases yet to be created by an application. If an application calls this function with a nonzero integer (true) as argument, databases subsequently created by the current execution of the application will be in incremental mode, and the schema of the creating application will be installed incrementally. This function is declared
static void objectstore::set_incremental_schema_installation(
os_boolean
) ;
sizeof(T1) == sizeof(T2)then and only then would T1 and T2 verify validly. Consequently,
T1 == T2and
n1 == n2(Strictly speaking, short, int, and long are the same as signed short, signed int, and signed long respectively.)
T1 == T2or T1 and T2 are covered by rules 2, 3, 4, or 5 above. That is, T1 and T2 are integral types of the same size.
If you use the simple form of persistent new described in Persistent new and delete (specifying only a database, not a segment), the new object is stored in the default segment. This segment, like all segments, expands to accommodate whatever new data is stored in it. If you want a database to have a new segment, you create it using the member function os_database::create_segment().
os_segment *create_segment() ;The function os_database::create_segment() takes as this argument a pointer to the database in which the segment is to be created. This function takes no other arguments. It returns a pointer to an instance of the system-supplied class os_segment.
As with instances of os_database, the segment object is actually transient, unlike the segment it stands for. That is, it exists only for the duration of the current process. If you copy it into persistent storage, it will be meaningless when retrieved by another process.
See Basic Clustering, as well as Creating Object Clusters in Chapter 1, Advanced Persistence, of the ObjectStore Advanced C++ API User Guide.
Referring Across Databases and Transactions
If you want to use cross-database pointers, you can specify particular databases or segments as allowing such pointers. This is done with the function os_database::allow_external_pointers() or os_segment::allow_external_pointers(). These functions must be called from within a transaction. allow_external_pointers()
void allow_external_pointers() ;Here is an example of a call to the os_database::allow_external_pointers() function.
#include <ostore/ostore.hh>
#include "part.hh"
void f() {
objectstore::initialize();
static os_database *db1 = os_database::open("/thx/parts");
OS_BEGIN_TXN(tx1, 0, os_transaction::update)
db1->allow_external_pointers();
/* now cross-database pointers from db1 are allowed */
. . .
OS_END_TXN(tx1)
db1->close();
}
Once you perform allow_external_pointers() on a database, the current process and subsequent processes can store cross-database pointers there. When you access a cross-database pointer, if the database it points to is not open, it is opened automatically.There is a small performance cost to allowing cross-database pointers. Allowing external pointers augments the entries in the tables that associate virtual memory addresses with on-disk object locations. This slightly increases the time it takes for ObjectStore to transfer data into memory.
This increase applies to all data stored in the database from which external pointers are allowed. You can localize the performance cost by allowing external pointers from a particular segment or segments rather than from the entire database.
#include <ostore/ostore.hh>
#include "part.hh"
void f() {
objectstore::initialize();
static os_database *db1 = os_database::open("/thx/parts");
static os_segment *seg1 = db1->get_default_segment();
OS_BEGIN_TXN(tx1, 0, os_transaction::update)
seg1->allow_external_pointers();
/* now cross-database pointers from seg1 are allowed */
. . .
OS_END_TXN(tx1)
db1->close();
}
In addition to localizing the performance cost, allowing cross-database pointers on a per-segment basis gives you greater control over integrity management, since what counts as an illegal pointer can be different from segment to segment within the same database.Cross-database pointers are resolved according to the relative pathname of the database containing the referenced data. See Cross-Database Pointers and Relative Pathnames.
Cross-transaction pointers
You can also allow cross-transaction pointers in the current process by calling the static function objectstore::retain_persistent_addresses(). See Retaining Pointer Validity Across Transactions in Chapter 1, Advanced Persistence, of the ObjectStore Advanced C++ API User Guide.
ObjectStore references
If you only need to refer across databases in a few cases, you can avoid the slight performance cost of allowing cross-database pointers from an entire database or segment by using ObjectStore references instead. You can also use ObjectStore references to refer across transaction boundaries on a case-by-case basis, instead of using retain_persistent_addresses(). See Using ObjectStore References in Chapter 1, Advanced Persistence, of the ObjectStore Advanced C++ API User Guide.
Cross-Database Pointers and Relative Pathnames
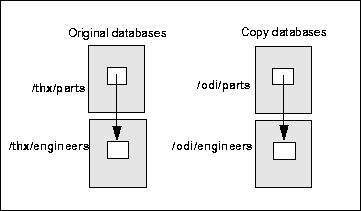
Cross-database pointers are resolved according to the relative pathname of the database containing the referenced data. For example, suppose a database with pathname /thx/parts contains a pointer to data in a database with pathname /thx/engineers. Since these two databases have a common ancestor directory (/thx), pointers to /thx/engineers are resolved according to the relative pathname ../engineers. (Remember that pathnames of ObjectStore directories and databases use slashes no matter which operating system is being used, and pathnames always begin with a slash (/).)
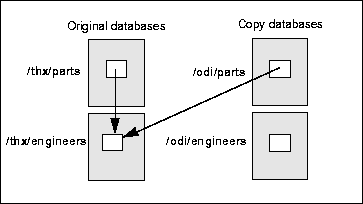
In practical terms, resolution by relative pathname can be understood as follows. Suppose that you copy the two databases /thx/parts and /thx/engineers, giving the copies the pathnames /odi/parts and /odi/engineers. Because resolution is by relative pathname, the copy of the outgoing pointer from the parts database will refer to data in the copy of the engineers database, /odi/engineers. If the cross-database pointer had been resolved according to the absolute pathname of the referent database, the copy of the pointer would have referred to data in the original database, /thx/engineers.
Resolution of cross-database pointers by relative pathname
Resolution of cross-database pointers by absolute pathname
Default Relative Directory
The pathname used in the default resolution procedure is relative to the lowest directory in the hierarchy that the two pathnames have in common. For example, if a pointer is stored in /A/B/C/db1 that refers to data in /A/B/D/db2, the lowest common directory is A/B, so the relative pathname ../../D/db2 is used to record the referent data's on-disk location. Specifying a Relative Directory
If you want, you can explicitly specify the relative directory by using the function os_database::set_relative_directory(). To see how this works, consider the previous example: you want to store a pointer in /A/B/C/db1 that refers to data in /A/B/D/db2. Suppose that you want the pointer resolved according to the relative pathname ../B/D/db2; that is, you want the relative directory to be /A (not /A/B as it would be in the default case). Example: setting the relative directory
#include <ostore/ostore.hh>
#include "part.hh"
void f() {
objectstore::initialize();
static os_database *db1 = os_database::open("/thx/parts");
static os_segment *seg1 = db1->get_default_segment();
OS_BEGIN_TXN(tx1, 0, os_transaction::update)
seg1->allow_external_pointers();
db1->set_relative_directory("/A"));
. . .
OS_END_TXN(tx1)
db1->close();
}
Then, for the rest of the process, cross-database pointers will be stored using pathnames that are relative to the directory you specified (/A in the example). When a process sets the relative directory, the effect is local to that process. Other processes, including concurrent ones, can set a different relative directory or use the default behavior.If you specify null (0) instead of a string as the argument to os_segment::set_relative_directory(), the default procedure is used to determine the relative directory.
However, ObjectStore's fault handler is circumvented for cases in which you pass a persistent pointer to one of the following:
To ensure that data is accessible during a system call, create an automatic os_with_mapped object, specifying the starting address and size of the range you want to pass to a system call, and whether you intend to update the object.
Within the scope of the os_with_mapped object, the referenced range is available to the system call. For example:
{
os_with_mapped mybuf(persistent_buffer, buffer_size, 1);
read(fd, persistent_buffer, buffer_size);
}
The constructor for os_with_mapped ensures that the necessary pages are available and mapped with appropriate access rights, and that those pages are wired into the client cache until the destructor is run. The constructor signals an exception if you run out of room in the cache, if you attempt to wire a page more than 250 times, or if obtaining a page fails because of deadlock.The destructor allows the pages to be moved out of the cache again as necessary.
Object Design recommends the use of os_with_mapped whenever you pass a persistent pointer to system calls or library functions that might call system calls or handle memory access violations. There is little overhead to os_with_mapped, so calling it frequently does not generally present a performance problem.
Mapping large ranges, having many simultaneous mappings, or keeping mappings in effect for a long time is not recommended, because this can interfere with cache replacement and lead to a cache-is-full exception.
Updated: 03/31/98 16:55:02