ObjectStore C++ API User Guide
Chapter 1
ObjectStore Concepts
This chapter introduces the basic concepts you need to understand in order to use ObjectStore successfully. The information is organized as conceptual overviews of the following topics:
Persistent Storage
Persistent data is data that survives beyond the lifetime of the process that created it. ObjectStore stores persistent data in stable storage in databases, typically disks. There are two kinds of databases. A file database is a regular operating system file. A rawfs database resides in an ObjectStore file system managed by an ObjectStore Server. Rawfs databases are discussed further on page 5.
Each database is made up of segments, which are variable-sized regions of memory that can be used as the unit of transfer from persistent storage to program, or transient, memory. Each segment, in turn, is made up of pages. A specified number of pages can be used instead of segments as the unit of transfer to program memory.

ObjectStore Processes
ObjectStore
ObjectStore applications require two auxiliary processes for application execution - an ObjectStore Server and a Cache Manager. A Server handles access to ObjectStore databases, including storage and retrieval of persistent data. When ObjectStore is installed, the system administrator typically arranges for each Server to start when its host machine boots. A single application can use several databases, including databases on different file systems, handled by different Servers. Most users never have to worry about starting and stopping Servers.
A Cache Manager is started automatically when an ObjectStore application starts. The cache manager is a daemon that runs on the machine running the client application. Its function is to respond to Server requests as a stand-in for the client application, in order to participate in the management of the application's client cache. The client cache is the local holding area for data mapped or waiting to be mapped into virtual memory.
If additional ObjectStore applications are started on the same machine, the same Cache Manager functions similarly for these applications as well. Although the same machine can run several ObjectStore applications at once, only a single Cache Manager is ever running on a given machine. As with Servers, most users never have to worry about starting or stopping Cache Managers.
ObjectStore/Single
ObjectStore/Single applications have combined the Server and Cache Manager functions into one process. The diagrams that follow point out the distinctions between the ObjectStore and ObjectStore/Single implementations. It is important to remember that although the implementation differs, the functions performed by the Server and Cache Manager are preserved in ObjectStore/Single. For more information, see ObjectStore Building C++ Interface Applications, Chapter 6, Working with ObjectStore/Single.
ObjectStore processes
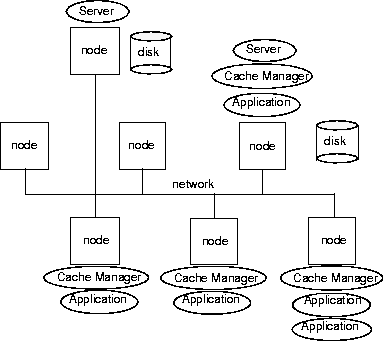
Each site has one or more Servers to handle persistent data. Each node running one or more ObjectStore applications has a Cache Manager to handle application data.
ObjectStore/Single process
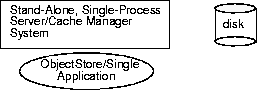
The nonnetworked ObjectStore/Single application provides the same functions, but the two processes have been combined into one.
Rawfs Databases
Using ObjectStore, you have the option of storing some or all of your databases in ObjectStore file systems managed by ObjectStore Servers instead of storing databases as regular files managed by the operating system. Each ObjectStore file system, known as a rawfs, is either a raw partition or an operating system file. For information on setting up and managing a rawfs, see ObjectStore Management, Chapter 1, Overview of Managing ObjectStore, Managing the Rawfs.
Each rawfs provides a separate name space and directory hierarchy. Rawfs directories form hierarchical structures just as operating system directories do. But rawfs directory hierarchies are independent of the operating system directory hierarchies.
Each ObjectStore Server can manage a hierarchy of rawfs directories, and maintains permission modes, creation dates, owners, and groups for each entry. There can be several independent rawfs directory hierarchies at a given site, each managed by a different Server, and the same application can use databases in different hierarchies.
ObjectStore/Single
Currently, ObjectStore/Single supports only file databases, not rawfs databases.
ObjectStore Memory Mapping Architecture
With ObjectStore, data is transferred between database memory and program memory completely automatically in a manner transparent to the user. ObjectStore detects any reference in a running program to persistent data, and automatically transfers the page containing the referenced data (possibly together with adjacent pages) across the network to the application's cache. Then the page containing the referenced data is mapped into virtual memory.
Sometimes the referenced data is already in the client cache (because data in the same pages was already used, and the required page was not swapped out of the cache), and all that is required is the virtual memory mapping. Sometimes the data is already mapped into virtual memory (because data on the same page was already used in the current transaction) and then nothing additional is required to access it. Once data has been mapped into virtual memory, access to it is as fast as access to regular, transient data.
The paragraphs that follow provide a summary of how the transfer of data between persistent and transient memory is handled.
ObjectStore achieves the combination of transparency and efficiency with a unique memory mapping architecture. All data is stored in an ObjectStore database in its native C++ format. All pointers in a database take the form of regular virtual memory pointers. The value of a pointer in a given segment is the segment's pseudoaddress for the object the pointer refers to.
Pseudoaddresses
A pseudoaddress is the identifier a segment uses for an object pointed to by that segment. Two pointers (pseudoaddresses) in the same segment have the same value if and only if they refer to the same object. But two pointers (pseudoaddresses) in different segments might have the same value and yet refer to different objects. And two pointers (pseudoaddresses) in different segments might have different values and yet refer to the same object. This is what makes relocation necessary.
Relocation is the process of changing the pointers on a page of data as it is mapped into the client cache or unmapped from the client cache. Here is how relocation works.
Persistent relocation map (PRM)
Each segment has an associated persistent table, the persistent relocation map (PRM), that allows determination of an object's on-disk location (that is, database name, segment number, and offset), given its pseudoaddress. The PRM does not actually have an entry for each different pseudoaddress. Instead, each entry covers a range of pseudoaddresses.
When a page of data is mapped into the cache, all pseudoaddresses on the page must be converted into virtual addresses within the process's persistent address space region. Within a transaction, a single unified mapping (across all segments) that establishes the translation between database location (again, database name, segment number, and offset) to virtual address is built up. Also, for each segment, a transient mapping that establishes the direct bidirectional translation between pseudoaddresses and virtual addresses is built up. The manner in which these mappings are built depends on whether the segment is using
With immediate assignment, a segment's whole PRM is incorporated into the unified mapping, and the whole pseudoaddress-to-virtual-address mapping for that segment is built prior to the first time any page in that segment is mapped into the cache.
With deferred assignment, the unified mapping and the pseudoaddress-to-virtual-address mapping are augmented from the segment's PRM as necessary to translate each pseudoaddress encountered during the relocation. In both cases, each pointer (pseudoaddress) on the page being relocated is changed to the virtual address determined by its on-disk location and the transient mappings described above. Once inbound relocation is complete, the page is mapped into virtual memory at the location assigned it by the unified mapping.
Outbound relocation
When a modified page is written to the database, outbound relocation is performed on it, which causes its pointers to be changed back to their original pseudoaddresses. Any new pointers to on-disk locations not yet assigned pseudoaddresses cause the page's PRM to be augmented with new entries.
Transient relocation map (TRM)
In some cases, ObjectStore skips outbound relocation, because it knows that the page's pointers and the corresponding pseudoaddresses are the same (this is determined by ObjectStore during inbound relocation). In such a case, the PRM is augmented with entries to accommodate all on-disk locations currently in the in-use transient relocation map (TRM).
Advantages of this architecture
Two of the major advantages of this architecture can be described as follows:
Memory Mapping and Schema Information
For ObjectStore to realize the advantages inherent in this memory mapping architecture, it needs to store schema information in each database - that is, it needs to store information in each database about the classes of objects stored there, and the layout of instances of these classes. This allows ObjectStore to identify the locations of pointer fields in each newly retrieved segment (so it can perform relocation).
ObjectStore stores schema information as C++ objects. Classes themselves are not run-time objects in C++ (they cannot, for example, be values of variables or other expressions). So ObjectStore must generate representations of classes in order to manage database memory.
These representations are generated, before link time, for each application that might store information in a database. So, at run time, when the application stores an object in a database, a representation of the object's class is ready to be added to the database's schema along with the object itself; or, if instances of that class are already in the database, the application's class representation is checked against that of the database to make sure they agree.
An application's schema information (generated by the ObjectStore schema generator) is stored in two places: a source file and an ObjectStore database. Because you must use the schema generator when building an ObjectStore application, you are making use of ObjectStore's database management capabilities, which are described in ObjectStore Management.
Generating Schemas for ObjectStore Applications
Building an ObjectStore application has a step not associated with regular, nondatabase C++ applications: the generation of schema information. This process is performed by the ObjectStore schema generator, and produces both an ObjectStore database, known as the application schema database, and an object file, the application schema source file.
Input to Schema Generation
The input to schema generation consists of schema source files, possibly together with library schemas. Schema source files are files you provide. In them, you list those classes whose instances are created and stored in persistent memory by the application, or whose instances serve as entry points into persistent memory (see Database Entry Points and Data Retrieval). The schema source file that you provide should include additional information if you use either ObjectStore dictionaries (see Dictionaries), or query functions (see Chapter 5, Queries and Indexes, in the ObjectStore Advanced C++ API User Guide).
By performing a transitive closure operation, the schema generator determines all those classes reachable by navigation from the classes in the schema source file, and adds information about them to the application schema database.
Library schemas are ObjectStore databases that contain schema information for libraries that store or retrieve persistent data. ObjectStore provides library schemas for its libraries. You can also use the schema generator to generate library schemas for other libraries.
Schema Generator Output
The application schema source file is an output file that is created by the ObjectStore schema generator, and must be compiled and linked with your application. This file records the location of the application schema database and the names of the application's virtual function dispatch tables. It also contains discriminant functions for anonymous unions.
For complete instructions on building ObjectStore applications and libraries, see ObjectStore Building C++ Interface Applications. In particular, there is a good summary of tasks in Chapter 1, Overview of Building an Application. The process of schema generation itself is discussed in detail in Chapter 3, Generating Schemas, of that publication.
Programming Interface
The ObjectStore C++ interface is designed for the development of C++ and C applications that require database services. Although some of your interaction with ObjectStore takes place from the shell (you issue commands, for example, to create rawfs directories or generate schemas), most of it takes place from within programs.
With ObjectStore and ObjectStore/Single, you can use a variety of C++ compilers, together with the C++ library interface. This is a library of classes whose member functions, data members, and enumerators provide access to database functionality. Also included are global functions, such as an overloading of operator new() that allows dynamic allocation of persistent memory for any type of object.
The class templates feature of C++ is included in the ANSI Standard for C++. If you are using a compiler that supports templates, you can use the parameterized versions of some classes in the class library. Using parameterized classes enhances the type safety of your applications.
[previous] [next]
Copyright © 1997 Object Design, Inc. All rights
reserved.
Updated: 03/31/98 16:53:06