ObjectStore C++ API User Guide
Chapter 8
Schema Evolution
This chapter provides an introduction to ObjectStore schema evolution. Schema evolution is a complex facility; only the most basic schema evolution operations are discussed in this chapter. Detailed coverage of this topic is found in Chapter 9, Advanced Schema Evolution, in the ObjectStore Advanced C++ API User Guide.
The material is organized in the following manner:
What Is Schema Evolution?
The term schema evolution refers to the changes undergone by a database's schema during the course of the database's existence. It refers especially to schema changes that potentially require changing the representations of objects already stored in the database.
ObjectStore provides some basic utilities to use in uncomplicated circumstances, as well as a schema evolution interface that lets you write a specialized schema evolution application. With these tools, you can redefine the classes in a database's schema to accommodate changes. ObjectStore can modify the schema and change the representations of any existing instances in the database to conform to the new class definitions.
Without the the schema evolution facility, you can only change a database schema by adding new classes to it. You cannot redefine a class already contained in the schema, except in ways that do not affect the layout that the class defines for its instances. For example, adding a nonstatic data member changes instance layout, but adding a nonvirtual member function does not.
Making Use of Schema Evolution
It is difficult to predict exactly when you might need to redefine a class or classes in a database. Schema evolution is a complex operation. If it requires that you write a special schema evolution application, the process must be planned and executed very methodically with many checkpoints along the way. Schema evolution is a very powerful tool. It allows you to change the semantics of the objects in your database. As such, it poses the very real danger of user-introduced data corruption.
Planning Your Schema Evolution
As you develop and implement your schema evolution plan, you must ensure that
When planning your schema evolution, it is essential to anticipate all your requirements for the evolution, and to plan your application carefully around the desired outcome. A good rule of thumb is to try your schema evolution application on small databases to investigate the process, determine what works, and locate anything that might introduce complications.
Planning in the development phase of schema evolution is critical, but of equal importance are careful testing and validation of your implementation using a variety of methods. A conservative approach is best, so plan for the stages of your schema evolution project in the following sequence.
Restriction note
When planning a schema evolution, be aware that if the database is greater than n% of OS_AS_SIZE (the environment variable establishing the size of the client's persistent storage space), schema evolution does not work. The value of n% varies greatly depending on the specifics of the applications involved. Consult Object Design Technical Support for advice about the amount of persistent storage space required by schema evolution for your particular configuration.
Regardless of the method used to perform schema evolution, before evolution starts, use the osverifydb -all utility to check for database errors. (See Using osverifydb to Verify Pointers and References.)
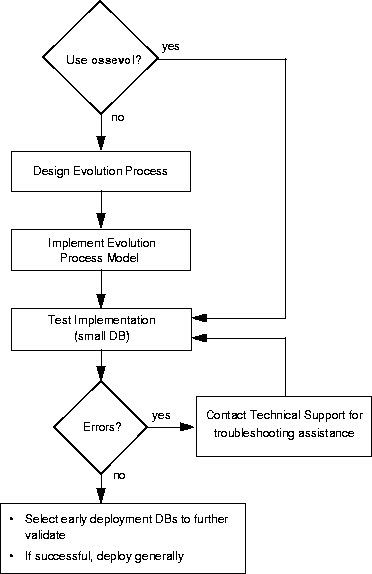
Sequence of Planning Your Schema Evolution
- Determine if you can use the ossevol utility to update a database's schema, or if you must design a special schema evolution application. You cannot, for example, use ossevol to update a database if the database contains instances of os_Dictionary or os_rDictionary. (See Schema Evolution with ossevol for more information).
- Plan the schema evolution model in cases where you require a special application.
- Implement your design.
- Test your implementation and troubleshoot.
- If the facility is to be used to upgrade databases currently in use, obtain some active databases for predeployment validation.
- Limit your initial deployment to validated customers, followed by general deployment to all customers.
Schema evolution decision tree
Schema Evolution with ossevol
The ossevol utility modifies a database and its schema so that it matches a revised application schema. It handles many common cases of schema evolution. Running the ossevol utility changes the physical structure of your database, so the importance of backing up your database before running this utility is critical.
Use this utility when you are performing simple operations such as adding or deleting data members that do not require a special evolving application.
Evolving schemas that contain dictionaries
To evolve the schema of a database that contains instances of os_Dictionary or os_rDictionary, you cannot use the ossevol utility; you must create a schema evolution application. See Implementing Schema Evolution.
ossevol Options
The ossevol options are described in the following table, and further information is available in ObjectStore Management, Chapter 4, Utilities. Object Design recommends that you use the -task_list option to make sure you understand the steps that the evolution will be taking before actually performing the schema evolution.
Once you have completed the schema evolution process, you can use osscheq (see Using osscheq to Verify Schema Changes) and osverifydb (see Using osverifydb to Verify Pointers and References) to compare the old and new schemas, and to verify that the pointers and references are sound.
Using osscheq to Verify Schema Changes
The osscheq utility is useful in detecting whether a change to a schema causes it to be incompatible with the other schemas in an application. Check for any incompatibilities immediately following schema evolution. When schemas are not compatible, execution of the application fails because of a schema validation error.
Invoke the osscheq utility as follows:
osscheq test1 test2
Comparison technique
The comparison technique depends on the types of schemas being compared. When comparing compilation or application schemas, ObjectStore uses the technique used by the schema generator when building compilation or application schemas. When one of the schemas being compared is a database schema, the comparison technique is the same as that used to validate an application when it accesses a database.
This form of checking is the minimal checking required to ensure that the application and the database use the same layout for all shared classes.
A complete description of osscheq and other ObjectStore utilities can be found in Chapter 4, Utilities, of ObjectStore Management.
Using osverifydb to Verify Pointers and References
This utility verifies all pointers and references in a database. Using this utility prior to attempting schema evolution and again after schema evolution establishes that the database pointers and references are sound. The options available for this utility and additional information are available in ObjectStore Management, Chapter 4, Utilities.
Also run any application-specific verification tools available. This is particularly important because osverifydb can only detect problems at a fairly low semantic level.
Designing a Schema Evolution Application
The most important factor in planning schema evolution is the time and attention you apply to the details involved in your particular application. Plan the schema evolution of your application with the utmost care. What are the specific objectives your schema evolution application must accomplish?
Determine, for example, if you must write an evolution application or if you can accomplish your objective using the ObjectStore utility ossevol. For the most part, if you are adding or deleting a data member, you might make use of this utility. This depends on the kind of data member, however. A data member that requires a nondefault value (nonzero), or the need to add a C++ reference, would require that you write a special schema evolution application.
Example Using ossevol for Schema Evolution
Changing a class value
As a simple illustration, suppose that a customer database uses address objects that have a field for a five-digit ZIP code. With the schema evolution facility, you can change the definition of the class address so that the value type of the data member address::zip_code is char[9] instead of char[5] - or, better yet, you can use a new or existing class, string or zip_code, to serve as the new value type in place of char[5].
If you invoke schema evolution on the database, using the new class definitions, ossevol modifies the database's schema and changes each address object to use the new type of object for its address::zip_code (adjusting the size of the address::zip_code field, if necessary).
The value contained in the new field can either be determined by a user-defined routine that has access to the unevolved data, or it can be set automatically. When set automatically, the new value is set by assignment from the old value, if possible, and otherwise it is set to a default value (such as 0 or the result of executing a constructor that initializes each member to 0).
Implementing Schema Evolution
If you have determined that you cannot achieve your objectives using the ObjectStore utility ossevol, you must then plan the specific steps required for your application's schema evolution. Be sure to include all the phases of preparation and testing described in this section.
Because of the potential complexity of the schema evolution process, it is important to incorporate as many safeguards as possible into your schema evolution application, to test it thoroughly using small databases, and to validate that the schema evolution has been successful. This chapter provides basic guidelines, examples, and validation techniques.
For explanations and examples of more complex schema evolution issues, see Chapter 9, Advanced Schema Evolution, in the ObjectStore Advanced C++ API User Guide.
The Schema Evolving Application
What to include
Regardless of the evolution you intend to perform, make sure you plan to include the following in your evolution application:
What to avoid
Delete os_cursor objects before schema evolution (schema evolution cannot handle os_cursor objects).
Unions require a very complicated custom schema evolution application.
Validation Activities
The following is a checklist of validation tasks you should perform to confirm that the schema evolution actually accomplished your objectives and did not make unexpected alterations to the database.
Testing
Some additional testing you can perform to ensure that the database is as you expect includes
Troubleshooting
If you encounter difficulties when performing or testing the results of any schema evolution operation, you must debug carefully with the assistance of Object Design Technical Support. You must supply support with the
Deploying Schema Evolution
Once you are satisfied that the schema evolution application you have designed and tested is accomplishing your objectives successfully, you can begin deployment. It is advisable to do this in phases as well.
First get some of your customers' databases and initiate schema evolution on those databases. Validate the results.
General deployment tip
Be sure to deploy in stages by validating that your schema evolution application works on several small customer databases before you make it generally available.
[previous] [next]
Copyright © 1997 Object Design, Inc. All rights
reserved.
Updated: 03/31/98 17:03:18