This chapter provides information about the ObjectStore schema evolution facility. For a basic understanding of tasks you must perform to complete a schema evolution project, see Chapter 8, Schema Evolution, in the ObjectStore C++ API User Guide.
The information about schema evolution is organized in the following manner:
Instance migration itself has two phases:
In most cases, new fields are initialized with zeros. There is one useful exception to this, however. In the case where a field has changed type, and the old and new types are assignment compatible, the new field is initialized by assignment from the old field value.
The initialization rules are discussed in Instance Initialization Rules.
Pointers to Modified Objects and Their Subobjects
During the initialization phase, the address of an instance being migrated generally changes. The reason for this is that migration actually consists of making a copy of the old unmigrated instance, and then modifying this copy. The copy and the old instance will be in the same segment, but their offsets within the segment will be different. Illegal Pointers
During this process of adjusting pointers to modified instances, ObjectStore might detect various kinds of illegal pointers. For example, it might detect a pointer to the value of a data member that has been removed in the new schema. Since the data member has been removed, the subobject serving as the value of that data member is deleted as part of instance initialization. Any pointer to such a deleted subobject is illegal, and is detected by ObjectStore. C++ References
C++ references are treated as a kind of pointer. References to migrated instances are adjusted just as described above. Illegal references are detected and can be handled as described. ObjectStore References
In addition, as with pointers, ObjectStore references to migrated instances are adjusted to refer to the new instance rather than the old. You are given an option concerning local references. Recall that to resolve a local reference you must specify the database containing the referent. If you want, you can direct ObjectStore to resolve each local reference using the database in which the reference itself resides. If you do not use this option, local references will not be adjusted during instance initialization (but you can provide a transformer function so that they are adjusted during the instance transformation phase; see Instance Transformation).
As with pointers, you can supply handler functions for illegal references. If you do not supply an illegal reference handler, evolution continues uninterrupted when an illegal reference is encountered. The reference is left unmodified and no exception is signaled.
Obsolete Indexes and Queries
Just as some pointers and references become obsolete after schema evolution, so do some indexes and persistently stored queries. For example, the selection criterion of a query or the path of an index might refer to a removed data member. ObjectStore detects all such queries and indexes. In the case of an obsolete query, ObjectStore internally marks the query so that subsequent attempts to use it cause a run-time error.
Instance Reclassification
The schema evolution facility allows for one special form of instance migration, which allows you to reclassify instances of a given class as instances of a class derived from the given class. This form of migration is special because it is not, strictly speaking, a case of modifying instances to conform to a new class definition. However, instance reclassification is typically desirable when new subclasses are added to a schema. Instances of the base class can be given a more specialized representation by being classified as instances of one of the derived classes.
Task List Reporting
To help you get an overall picture of the operations involved in instance initialization for a particular evolution, the schema evolution facility allows you to obtain a task list describing the process. The task list consists of function definitions indicating how the migrated instances of each modified class will be initialized. You generate this list without actually invoking evolution, which allows you to verify your expectations concerning a particular schema change before migrating the data.
Instance Transformation
For some schema changes, the instance initialization phase is all that is needed. But in other cases, further modification of class instances or associated data structures is required to complete the schema evolution. This further modification is generally application dependent, so ObjectStore allows you to define your own functions, transformer functions, to perform the task. Transformer Functions
You associate exactly one transformer with each class whose instances you want to be transformed. During the transformation phase of instance migration, the schema evolution facility invokes each transformer function on each instance of the function's associated class, including instances that are subobjects of other objects.
In addition, transformers are useful for updating data structures that depend on the addresses of migrated instances. A hash table, for example, that hashes on addresses should be rebuilt using a transformer. Note that you do not need to rebuild a data structure if the position of an entry in the structure does not depend on the address of an object pointed to by the entry, but depends instead, for example, on the value of some field of the object pointed to. Such data structures will still be correct after the instance initialization phase.
Using transformers is discussed in Using Transformer Functions.
Initiating Evolution with evolve()
To perform schema evolution, you make and execute an application that invokes the static member function os_schema_evolution::evolve(). The function must be called outside the dynamic scope of a transaction. The application must include the header file ostore/schmevol.hh and link with the libraries libosse.a, liboscol.a, and libos.a.
static void evolve(
const char *workdb_name,
const char *db_to_evolve
);
static void evolve(
const char *workdb_name,
const os_collection &dbs_to_evolve
);
The evolution process depends on three parameters:
If you do not specify any database to evolve (that is, if you supply 0 for the first overloading, or an empty collection for the second overloading), err_schema_evolution is signaled.
The schema modifications are, by default, specified by the schema of the application that calls evolve(). So the schema source file for this executable should contain a new class definition for each class that you want to modify.
If you want, you can specify the schema modifications with a call to the static member function os_schema_evolution::set_evolved_schema_db_name() before calling evolve(). This function takes a const char* as argument, the pathname of a compilation or application schema database (the compilation or application schema database for some other application).
static void augment_classes_to_be_removed(
const char *name_of_class_to_be_removed
);
The calls should precede the call to evolve().You can also call this function once for all the classes to be removed, if you pass an os_Collection<char*> containing the names of all the classes to be removed. In this case you use the overloading
static void augment_classes_to_be_removed(
const os_Collection<char*>
&names_of_classes_to_be_removed
);
Again, this call should precede the call to evolve().
When evolution is interrupted, the work database records a consistent intermediate state of the evolution process. Subsequently calling evolve() using the same work database will cause evolution to be resumed from the point of interruption.
Resolution of Local References
As mentioned earlier, you are given an option regarding the resolution, during evolution, of local ObjectStore references. (Recall that the referent's database must be specified for resolution of local references.) If you call the static member function os_schema_evolution::set_local_references_are_db_relative(), supplying a nonzero int (true) as argument, local references will be resolved using the database in which the reference itself resides. Otherwise local references will not be adjusted during the instance initialization phase (see Illegal Pointers).
Example: Changing the Value Type of a Data Member
Consider an example that involves changing the value type of a data member. Existing part class definition
class part {
public:
short part_id;
part(short id) { part_id = id; }
static os_typespec *get_os_typespec();
}
And you want to change the definition to be as follows:
class part {
public:
long part_id;
part(long id) { part_id = id; }
static os_typespec *get_os_typespec();
}
Here, the value type of the data member part_id has changed from short to long. The constructor's argument type has also changed. Since C++ provides a standard conversion from short to long, migrated instances of the class part will have their part_id fields initialized by assignment from the value of part_id in the corresponding old unmigrated instance.
#include <ostore/ostore.hh>
#include <ostore/coll.hh>
#include <ostore/schmevol.hh>
#include "part1new.hh" /* the new definition */
main() {
objectstore::initialize();
os_schema_evolution::evolve(
"/example/workdb",
"/example/partsdb"
);
}
Note that the header file ostore/schmevol.hh is included.Here, the argument /example/workdb is a name for the scratch pad database, and the argument /example/partsdb specifies the database to be evolved.
#include <ostore/ostore.hh>
#include <ostore/coll.hh>
#include <ostore/schmevol.hh>
#include "part1new.hh" /* the new definition */
main() {
objectstore::initialize();
os_collection::initialize();
os_Collection<char*> the_dbs_to_evolve;
the_dbs_to_evolve |= "/example/partsdb1";
the_dbs_to_evolve |= "/example/partsdb2";
the_dbs_to_evolve |= "/example/partsdb3";
os_schema_evolution::evolve(
"/example/workdb",
the_dbs_to_evolve
);
}
Note that both versions of the main() program include the new definition of the modified class. The schema source file for this executable should also contain the new definition of the class part.
#include <ostore/ostore.hh>
#include <ostore/coll.hh>
#include <ostore/manschem.hh>
#include "part1new.hh" /* this contains the new definition */
void dummy() {
OS_MARK_SCHEMA_TYPE(part);
}
The instance migration phase of the schema evolution process will migrate the parts in /example/partsdb (for the first version of main()), changing the size of the part_id field from the size of an int to the size of a long. As mentioned, the instance migration process will also initialize the field by assignment from the preevolution value. This happens for all instances of the class part.Note that the constructor for the new version of the class has no bearing on the initialization of migrated instances. The existing instances of the modified class are initialized according to the rules of default initialization described here. The new constructor initializes only those instances of the class that are created after evolution has occurred.
ossevol /example/workdb /example/ex1.comp_schema_db /example/partsdbFor information on the ossevol utility, see Schema Evolution with ossevol in Chapter 8 of the ObjectStore C++ API User Guide.
Using Transformer Functions
The instance initialization phase leaves migrated instances in a well-defined state. But if you want to perform further application-specific processing on these instances as part of the migration process, you can supply transformer functions to accomplish this.
As part of the instance migration process, the ObjectStore schema evolution facility invokes each transformer function on each instance of its associated class. This includes each instance that is embedded in some other object, either as the value of a data member or as the subobject corresponding to a base class of the object's class.
Signature of Transformer Functions
Transformers are functions with no return value and one argument of type void*. This argument is a pointer to the object being transformed, an instance of the new class that has already undergone instance initialization. Form of the call
void my_transform_function(void *the_new_obj)Transformer functions frequently perform processing that is based on the state of the old unevolved object corresponding to the object being operated on. The evolution facility provides a means of accessing the old object. This is discussed in the next section, Accessing Unevolved Objects.
Associating a Transformer with a Class
With the transform function defined, you can associate the function with a class and invoke the evolution process. The association is made by calling the static member function os_schema_evolution::augment_post_evol_transformers() in the application performing evolution. The call should be made before the call to os_schema_evolution::evolve(). augment_post_evol_transformers() function
The function augment_post_evol_transformers() has the following two overloadings:
static void
os_schema_evolution::augment_post_evol_transformers(
const os_transformer_binding&
);
static void
os_schema_evolution::augment_post_evol_transformers(
const os_Collection<os_transformer_binding*>&
);
os_transformer_binding("part", part_transform)
So a typical call to augment_post_evol_transformers() would be
os_schema_evolution::augment_post_evol_transformers (
os_transformer_binding("part", part_transform)
);
static void
os_schema_evolution::augment_classes_to_be_recycled(
const char *name_of_class_to_be_recycled
);
The calls should precede the call to evolve().You can also call this function once for all the classes to be recycled, if you pass an os_Collection<char*> containing the names of all the classes to be recycled. In this case you use the overloading
static void
os_schema_evolution::augment_classes_to_be_recycled(
const os_Collection<char*>
&names_of_classes_to_be_recycled
);
Again, this call should precede the call to os_schema_evolution::evolve().Note that the old unevolved instances of each modified class are deleted following completion of the transformation phase, whether or not you have specified the class as one to be recycled.
os_typed_pointer_void old_obj_typed_ptr =
os_schema_evolution::get_unevolved_object(a_new_obj);
void *an_old_obj = old_obj_typed_ptr;
This works because the class os_typed_pointer_void defines operator void*() to return the pointer.
const os_class_type &c = old_obj_typed_ptr.get_type();You retrieve a pointer to the object representing the data member of a specified name defined by a specified type using os_class_type::find_member().
os_fetch(the_old_obj, *c.find_member("part_id"), the_old_val);
As mentioned earlier, the instance initialization phase of evolution automatically modifies all pointers to instances of modified classes so that they reference the new migrated instances. This is true even for pointers contained in old unmigrated instances. So if you access an old data member during the instance transformation phase, and the value of the member is a pointer to an instance of a class that was also modified, the value you retrieve will point to the new migrated instance (see Example: Changing Inheritance).
Functions used to access unevolved objects
Here are the declarations of the functions used to access unevolved objects:
static os_typed_pointer_void os_schema_evolution::
get_unevolved_object(void *new_obj);
os_typed_pointer_void::operator void*() const;
const os_type &os_typed_pointer_void::get_type() const;
const os_member *os_class_type::
find_member(const char *name) const;
There is also a function for retrieving the address of the new version of a specified unevolved object, get_evolved_object().
void *os_fetch(
const void *p, const os_member_variable&, void *&value);
unsigned long os_fetch(
const void *p, const os_member_variable&,
unsigned long &value);
long os_fetch(
const void *p, const os_member_variable&, long &value);
unsigned int os_fetch(
const void *p, const os_member_variable&,
unsigned int &value);
int os_fetch(
const void *p, const os_member_variable&, int &value);
unsigned short os_fetch(
const void *p, const os_member_variable&,
unsigned short &value);
short os_fetch(
const void *p, const os_member_variable&, short &value);
unsigned char os_fetch(
const void *p, const os_member_variable&,
unsigned char &value);
char os_fetch(
const void *p, const os_member_variable&, char &value);
float os_fetch(
const void *p, const os_member_variable&, float &value);
double os_fetch(
const void *p, const os_member_variable&, double &value);
long double os_fetch(
const void *p, const os_member_variable&,
long double &value);
os_store(the_new_obj, c.find_member("part_id"), the_old_val);
Like os_fetch(), os_store() has an overloading for each built-in C++ type:
void os_store(
void *p, const os_member_variable&, const void *value);
void os_store(
void *p, const os_member_variable&,
const unsigned long value);
void os_store(
void *p, const os_member_variable&, const long value);
void os_store(
void *p, const os_member_variable&,
const unsigned int value);
void os_store(
void *p, const os_member_variable&, const int value);
void os_store(
void *p, const os_member_variable&,
const unsigned short value);
void os_store(
void *p, const os_member_variable&, const short value);
void os_store(
void *p, const os_member_variable&,
const unsigned char value);
void os_store(
void *p, const os_member_variable&, const char value);
void os_store(
void *p, const os_member_variable&, const float value);
void os_store(
void *p, const os_member_variable&, const double value);
void os_store(
void *p, const os_member_variable&,
const long double value);
void *os_fetch_address(void *p, const os_member_variable&);
const os_type &os_member_variable::get_type() const;Together with os_fetch(), these functions allow you to access not only data members, but also data members of data member values, and so on.
const os_base_class &os_class_type::find_base_class(
char *base_class_name) const;
void *os_fetch_address(
void *p, const os_base_class_variable&);
const os_class_type &os_base_class::get_class() const;
Suppose that instead of changing the value type of the class part (see the previous example) from short to long, you want to change it from short to char*, so arbitrary strings can be used for part IDs:
class part {
public:
short part_id;
part(short id) { part_id = id; }
static os_typespec *get_os_typespec();
}
class part {
public:
char *part_id;
part(char *id) {
int len = strlen(id) + 1;
part_id = new(
os_segment::of(this),
os_typespec::get_char(),
len
) char[len];
strcpy(part_id, id);
}
static os_typespec *get_os_typespec();
}
Since there is no standard C++ conversion from short to char*, the new field will be initialized to (char*) (0) during the instance initialization phase of schema evolution. But we can direct the evolution facility to overwrite this initialization during the transformation phase, and establish a new part_id value for a migrated instance based on the value of part_id for the corresponding unmigrated instance.To do this, supply a transformer function and associate it with the class part. As part of the instance migration process, the ObjectStore schema evolution facility will invoke this transformer function on each instance of the class.
#include <ostore/ostore.hh>
#include <ostore/coll.hh>
#include <ostore/schmevol.hh>
#include <ostore/mop.hh>
#include <stdio.h>
#include <string.h>
#include "part2new.hh"
static void part_transform(void *the_new_obj) {
/* get a typed ptr to the old obj */
os_typed_pointer_void old_obj_typed_ptr =
os_schema_evolution::get_unevolved_object(
the_new_obj);
/* get a void* ptr to the old obj; implicit operator void*() call */
void *the_old_obj = old_obj_typed_ptr;
/* get the type of the old obj */
const os_class_type &c = old_obj_typed_ptr.get_type();
/* get the old data member value */
int the_old_val;
os_fetch(the_old_obj, *c.find_member("part_id"),
the_old_val);
/* convert the old value to string form */
char conv_buf[16];
sprintf(conv_buf, "%d", the_old_val);
int len = strlen(conv_buf) + 1;
part *part_ptr = (part *)the_new_obj;
part_ptr->part_id =
new(os_segment::of(the_new_obj),
os_typespec::get_char(), len) char[len];
strcpy(part_ptr->part_id, conv_buf);
}
This function, part_transform(), sets the value of part_id in the new instance to the string denoting the integer value of part_id in the old unevolved instance. So, for example, if the old part_id was the integer 1138, the transformer sets the new part_id to a pointer to the character array 1138.With the transform function defined, you can associate the function with the class part and invoke the evolution process. As mentioned above, the association is made using a function call from within the application that invokes schema evolution.
Once the association between transformer and class is made, evolution is invoked.
#include <ostore/ostore.hh>
#include <ostore/coll.hh>
#include <ostore/schmevol.hh>
#include "part2new.hh"
main() {
objectstore::initialize();
/* associate part_transform() with the class part */
os_schema_evolution::augment_post_evol_transformers(
os_transformer_binding("part", part_transform)
);
/* initiate evolution */
os_schema_evolution::evolve(
"example/workdb", "example/partsdb"
);
}
Note that if the class part has classes derived from it, the instances of these derived classes must also be migrated, since each instance of the derived classes has a subobject corresponding to the base class part. The transformer part_transform() is run on these subobjects as well.
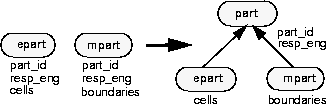
Consider a database schema that uses the classes epart, for electrical part, and mpart, for mechanical part, and suppose these classes both have data members for part_id and responsible_engineer. The example below shows how to add a common base class, part, to these two classes, and move the common data members out of the definitions of epart and mpart and into the definition of part.
This schema change involves redefining epart and mpart by
Note that the schema evolution facility does not view the old member epart::part_id as related to the new member part::part_id (and similarly for part::responsible_engineer). It would be undesirable for the facility to make any assumptions about the semantic relationship between the two members based merely on sameness of name, since this is an application-dependent matter.
Consequently, moving a data member from subtype to supertype should be viewed as deletion of the data member from the subtype, together with addition of a new, distinct data member to the supertype. Similar remarks apply for moving members the other way, from supertype to subtype.
Here are the old and new class definitions:
class epart {
public:
int part_id;
employee *responsible_engineer;
os_Collection<cell*> cells;
. . .
epart(int id, employee *eng) {
part_id = i;
responsible_engineer = eng;
}
};
class mpart {
public:
int part_id;
employee *responsible_engineer;
os_Collection<brep*> boundaries;
. . .
mpart(int id, employee *eng) {
part_id = i;
responsible_engineer = eng;
brep =0;
}
};
class part {
public:
int part_id;
employee *responsible_engineer;
part(int id, employee *eng) {
part_id = i;
responsible_engineer = eng;
}
};
class epart : public part {
public:
os_Collection<cell*> cells;
. . .
epart(int id, employee *eng) : part(id, eng) {}
};
class mpart : public part {
public:
os_Collection<brep*> boundaries;
. . .
mpart(int id, employee *eng) : part(id, eng) { brep =0; }
};
New schema source file
The schema source file for this executable should contain the new definitions of epart and mpart, as well as the definition of part.
#include <ostore/ostore.hh>
#include <ostore/coll.hh>
#include <ostore/manschem.hh>
/* these contain the new definitions */
#include "part.hh"
#include "new_epart.hh"
#include "new_mpart.hh"
static void dummy() {
OS_MARK_SCHEMA_TYPE(epart);
OS_MARK_SCHEMA_TYPE(mpart);
OS_MARK_SCHEMA_TYPE(part);
. . .
}
The instance migration phase of the schema evolution process modifies the instances of epart and mpart by eliminating the part_id and responsible_engineer fields from the subobject corresponding to the derived class. It also adds to each instance a subobject corresponding to the base class, and initializes it as if by a constructor that initializes each member to 0.
To do this, you supply a transformer function for each derived class, epart and mpart.
static void epart_transform(void *the_new_obj) {
/* get a typed ptr to the old instance */
os_typed_pointer_void old_obj_typed_ptr =
os_schema_evolution::get_unevolved_object(
the_new_obj
);
/* get a void* ptr to the old obj */
void *the_old_obj = old_obj_typed_ptr;
/* get the type of the old obj */
os_class_type &c = old_obj_typed_ptr.get_type();
/* get the old data member values */
int the_old_id_val;
os_fetch(
the_old_obj,
*c.find_member("part_id"),
the_old_id_val
);
void *the_old_resp_eng_val;
os_fetch(
the_old_obj,
*c.find_member("responsible_engineer"),
the_old_resp_eng_val
);
/* set the new data member values */
epart *epart_ptr = (epart*)the_new_obj
epart_ptr->part_id = the_old_id_val;
epart_ptr->responsible_engineer =
(employee*)the_old_resp_eng_val;
}
static void mpart_transform(void *the_new_obj) {
/* get a typed ptr to the old instance */
os_typed_pointer_void old_obj_typed_ptr =
os_schema_evolution::get_unevolved_object(
the_new_obj
);
/* get a void* ptr to the old obj */
void *the_old_obj = old_obj_typed_ptr;
/* get the type of the old obj */
os_class_type &c = old_obj_typed_ptr.get_type();
/* get the old data member values */
int the_old_id_val;
os_fetch(
the_old_obj,
*c.find_member("part_id"),
the_old_id_val
);
void *the_old_resp_eng_val;
os_fetch(
the_old_obj,
*c.find_member("responsible_engineer"),
the_old_resp_eng_val
);
/* set the new data member values */
mpart *mpart_ptr = (mpart*)the_new_obj;
mpart_ptr->part_id = the_old_id_val;
mpart_ptr->responsible_engineer =
(employee*)the_old_resp_eng_val;
}
Here, the transformer functions for the two classes need to do essentially the same thing. Each function retrieves the old values for part_id and responsible_engineer in the derived class, and sets the new values for part::part_id and part::responsible_engineer accordingly.Note that, if the current evolution calls for the migration of instances of the class employee, the value of responsible_engineer retrieved from the old instance will be a pointer to the new employee instance corresponding to the original data member value. This is because pointers to migrated objects are modified during the initialization phase to point to the new instances. This turns out to be convenient, since we are usually interested in the evolved version of the old data member value.
#include <ostore/ostore.hh>
#include <ostore/coll.hh>
#include <ostore/schmevol.hh>
#include "part.hh"
#include "new_epart.hh"
#include "new_mpart.hh"
main() {
objectstore::initialize();
/* associate epart_transform() with the class epart */
os_schema_evolution::augment_post_evol_transformers(
os_user_tranformer_binding("epart", epart_transform)
);
/* associate mpart_transform() with the class mpart */
os_schema_evolution::augment_post_evol_transformers(
os_user_tranformer_binding("mpart", mpart_transform)
);
/* perform the evolution process */
os_schema_evolution::evolve(
"/example/workdb", "/example/partsdb"
);
}
For databases undergoing the evolution described in this example, ObjectStore detects as illegal any pointers to eparts or mparts typed as void*. This is because, for example, before evolution such a pointer to an epart could also be interpreted as referring to the value of epart::part_id (since this int object starts at the same point as the epart), while after evolution it could no longer be interpreted as referring to that object. For more information on illegal pointers, see Illegal Pointers.
If the example is modified to include a leftmost base class for epart and mpart, both before and after evolution, void* pointers to eparts and mparts will not be illegal.
Instance Reclassification
As described above, the ObjectStore schema evolution facility allows you to migrate an instance to a subclass of its original class. This is particularly useful when new derived classes that are more appropriate classes for existing instances of the base class are added to a schema. Signature of Reclassification Functions
Reclassifiers are static functions with a return type of char* and one argument of type os_typed_pointer_void& (see Using Transformer Functions). This argument is a reference to a typed pointer to the object to be reclassified, an unevolved instance of the original class.
static char * my_reclassification_function(
os_typed_pointer_void &old_obj_typed_ptr
);
The return value, for a given instance, should be a string naming the new class the instance is to have. If the return value is 0, the instance will retain its current type.As with transformers, the schema for reclassification functions is the new schema. So to access fields of the object being reclassified, you must use os_typed_pointer_void::get_type(), os_class_type::find_member(), and os_fetch(). See Using Transformer Functions and the example in Example: Reclassifying Instances.
Associating a Reclassifier with a Class
With the reclassification function defined, you can associate the function with a class and invoke the evolution process. You make the association by calling the static member function os_schema_evolution::augment_subtype_selectors() in the application performing evolution. The call should be made before the call to evolve(). augment_subtype_selectors() function
The function augment_subtype_selectors() takes an instance of os_evolve_subtype_fun_binding as argument. You can construct an instance of this class by supplying a class name and a function pointer as arguments to the constructor, as in
os_evol_subtype_fun_binding("part", part_reclassifier)
So a typical call to augment_subtype_selectors() would be
os_schema_evolution::augment_subtype_selectors (
os_evolve_subtype_fun_binding("part", part_reclassifier)
);
In such a case, it might be desirable to modify this schema to include two new classes derived from part, epart (for electrical part) and mpart (for mechanical part). The data member cells can be moved out of part and into epart, and the member boundary_rep can be moved out of part and into mpart.
In addition to adding the subclasses to the schema, we should migrate existing instances of part so that those with a nonnull value for cells are reclassified as eparts, and those with a nonnull value for boundary_rep are reclassified as mparts.
The schema change in this example involves
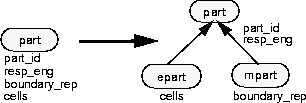
Again, note that moving a data member from supertype to subtype should be viewed as deletion of the data member from the supertype, together with addition of a new, distinct data member to the subtype.
class part {
public:
int part_id;
employee *responsible_engineer;
os_Collection<cell*> *cells;
brep *boundary_rep;
part(int id, employee *eng) {
part_id = i;
responsible_engineer = eng;
boundary_rep = 0;
}
};
class part {
public:
int part_id;
employee *responsible_engineer;
part(int id, employee *eng) {
part_id = i;
responsible_engineer = eng;
}
};
class epart : public part {
public:
os_Collection<cell*> *cells;
. . .
epart(int i) : part(i) { cells = 0; }
}
class mpart : public part {
public:
brep *boundary_rep;
. . .
mpart(int i) : part(i) { brep = 0; }
};
#include <ostore/ostore.hh>
#include <ostore/coll.hh>
#include <ostore/manschem.hh>
/* these contain the new definitions */
#include "new_part.hh"
#include "epart.hh"
#include "mpart.hh"
static void dummy() {
OS_MARK_SCHEMA_TYPE(epart);
OS_MARK_SCHEMA_TYPE(mpart);
OS_MARK_SCHEMA_TYPE(part);
}
The instance migration phase of the schema evolution process will modify the instances of part by eliminating the cells and boundary_rep fields. But first, you would like each part to be reclassified according to whether it uses the cells field or the boundary_rep field.
static char *part_reclassifier(
os_typed_pointer_void &old_obj_typed_ptr
) {
/* get a void* ptr to the old obj */
void *the_old_obj = old_obj_typed_ptr;
/* get the type of the old obj */
os_class_type &c = old_obj_typed_ptr.get_type();
/* get the old cells value */
os_Collection<cell*> *the_old_cells_val;
os_fetch(
the_old_obj,
*c.find_member("cells"),
the_old_cells_val
);
if (the_old_cells_val)
return "epart"; /* make it an epart */
/* get the old boundary_rep value */
brep *the_old_boundary_rep_val;
os_fetch(
the_old_obj,
*c.find_member("boundary_rep"),
the_old_boundary_rep_val
);
if (the_old_boundary_rep_val)
return "mpart"; /* make it an mpart */
return 0; /* leave it alone */
}
The reclassification of each part essentially amounts to supplementing it with a subobject corresponding to the derived class, epart or mpart. The subobject is initialized as if by a constructor that initializes each member to 0. We can overwrite this initialization by defining transformer functions for the derived classes.Note that the reclassification function is associated with the original class (the base class) of the instances it operates on, while the transformer functions (see below) are associated with the new classes (the derived classes) of the instances they operate on.
static void epart_transform(void *the_new_obj) {
/* get a typed ptr to the old instance */
os_typed_pointer_void old_obj_typed_ptr =
os_schema_evolution::get_unevolved_object(
the_new_obj);
/* get a void* ptr to the old obj */
void *the_old_obj = old_obj_typed_ptr;
/* get the type of the old obj */
os_class_type &c = old_obj_typed_ptr.get_type();
/* get the old data member values */
os_Collection<cells*> the_old_cells_ val;
os_fetch(the_old_obj,*c.find_member("cells"),
the_old_cells_val);
/* set the new data member value */
the_new_obj->cells = the_old_cells_val;
}
static void mpart_transform(void *the_new_obj) {
/* get a typed ptr to the old instance */
os_typed_pointer_void old_obj_typed_ptr =
os_schema_evolution::get_unevolved_object(
the_new_obj);
/* get a void* ptr to the old obj */
void *the_old_obj = old_obj_typed_ptr;
/* get the type of the old obj */
os_class_type &c = old_obj_typed_ptr.get_type();
/* get the old data member values */
brep *the_old_boundary_rep_ val;
os_fetch(
the_old_obj,
*c.find_member("boundary_rep"),
the_old_boundary_rep_val
);
/* set the new data member value */
the_new_obj->cells = the_old_boundary_rep_val;
}
#include <ostore/ostore.hh>
#include <ostore/coll.hh>
#include <ostore/schmevol.hh>
#include "part.hh"
#include "new_epart.hh"
#include "new_mpart.hh"
main() {
objectstore::initialize();
os_collection::initialize();
/* associate part_reclassifier() with the class part */
os_schema_evolution::augment_subtype_selectors(
os_evol_subtype_fun_binding("part", part_reclassifier)
);
/* associate epart_transform() with the class epart */
os_schema_evolution::augment_post_evol_transformers(
os_transformer_binding("epart", epart_transform)
);
/* associate mpart_transform() with the class mpart */
os_schema_evolution::augment_post_evol_transformers(
os_transformer_binding("mpart", mpart_transform)
);
/* perform the evolution process */
os_schema_evolution::evolve(
"/example/workdb",
"/example/partsdb"
);
}
static void os_schema_evolution::set_ignore_illegal_pointers(
os_boolean);
void function_name(
objectstore_exception &exc,
char *msg,
void *&the_bad_ptr
);
void function_name(
objectstore_exception &exc,
char *msg,
os_reference_local &the_bad_ref
);
void function_name(
objectstore_exception &exc,
char *msg,
os_reference &the_bad_ref
);
void function_name(
objectstore_exception &exc,
char *msg,
os_os_canonical_ptom &the_bad_ptr
);
void function_name(
objectstore_exception &exc,
char *msg,
os_database_root &the_bad_root
);
The os_schema_evolution class is described in Chapter 2, Class Library, of the ObjectStore C++ API Reference.
Besides the categorization we have been discussing, there is another, orthogonal way of dividing illegal pointers and references into categories. This division will help you understand what pointers and references get counted as illegal.
Typed pointers and references to deleted subobjects
The instance migration process deletes subobjects of instances of a given class when either
For example, a void* pointer to an instance of the class epart from the preevolution schema of Example: Changing Inheritance also points to the beginning of memory occupied by an int, the value of the member epart::part_id.
If a void* pointer is associated, before evolution, with an object with which it is not associated after evolution, the pointer is illegal and can result in the exception err_se_ambiguous_void_pointer.
Note that void* pointers appear in every database, since the values of database roots are typed as void*. They might be common in some databases, since in the underlying representations of ObjectStore collections, elements are typed as void*.
Example: Using Illegal Pointer Handlers
Consider the schema change made in Example: Changing Inheritance.
Changing epart and mpart to inherit from part
Changing epart and mpart to inherit from part; factoring out the common state to the base type.
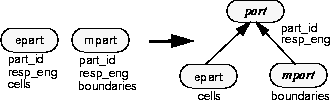
Example: using an illegal pointer handler
#include <ostore/ostore.hh>
#include <ostore/coll.hh>
#include <ostore/schmevol.hh>
#include <ostore/mop.hh>
#include <stdio.h>
#include <string.h>
#include "part5new.hh"
static void my_illegal_pointer_handler(
objectstore_exception& exc,
char* explanation,
void*& illegalp
) {
if (& exc == & err_se_ambiguous_void_pointer)
{
os_path * member_path =
os_schema_evolution::get_path_to_member(illegalp);
if (member_path)
{
char * path_string = os_schema_evolution::path_name(
* member_path);
if (strcmp(path_string, "epart.supplier_id") == 0 ||
strcmp(path_string, "mpart.supplier_id") == 0)
{
/* We know that these void * pointers in the */
/* pre-evolved world should be void * pointers */
/* to parts in the post-evolved world, so we set */
/* the pointer to the evolved object */
illegalp = (void *)
os_schema_evolution::
get_evolved_address(illegalp);
return;
} /* end if */
} /* end if */
} /* end if */
/* an unanticipated illegal pointer, signal the exception */
exc.signal(explanation);
}
#include <ostore/ostore.hh>
#include <ostore/coll.hh>
#include <ostore/schmevol.hh>
#include <ostore/mop.hh>
#include <stdio.h>
#include <string.h>
#include "part5new.hh"
main(int, char * argv[]) {
/* register the illegal pointer handler */
os_schema_evolution::set_illegal_pointer_handler(
my_illegal_pointer_handler
);
/* associate epart_transform with the class epart */
os_schema_evolution::augment_post_evol_transformers(
os_transformer_binding("epart", epart_transform)
);
/* associate mpart_transform with the class mpart */
os_schema_evolution::augment_post_evol_transformers(
os_transformer_binding("mpart", mpart_transform)
);
/* perform the evolution process */
os_schema_evolution::evolve(argv[2], argv[1]);
}
As with illegal pointers, you can handle obsolete queries or indexes by providing a special handler function for each purpose. If you do not supply handlers, ObjectStore signals an exception when it detects an obsolete query or index.
void function_name(os_coll_query &query,
const char *query_expr)
A reference to the obsolete query is passed in, together with a string expressing the query's selection criterion.
void function_name(os_collection &coll, const char *path_string)A reference to the collection indexed by the obsolete index is passed in, together with a string expressing the index's path (key).
class-name@[1]::initializer()where class-name names the function's associated class.
static void task_list(
const char *workdb_name,
const char *db_to_evolve
);
static void task_list(
const char *workdb_name,
const os_collection &dbs_to_evolve
);
static void set_task_list_file_name(const char *file_name);As with evolve(), the new schema is, by default, the schema of the application that calls task_list(), but you can specify the new schema with os_schema_evolution::set_evolved_schema_db_name() before calling task_list().
Also as with evolve(), you must specify the classes that are to be removed from the schema with os_schema_evolution::augment_classes_to_be_removed(). The calls should precede the call to task_list().
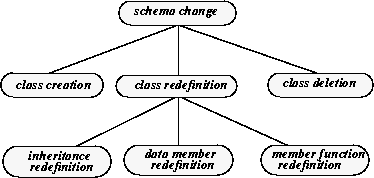
In general, inheritance redefinition includes changing a class to inherit from a new or existing class, and changing a class so that it no longer inherits from an existing class, or changing class inheritance from virtual to nonvirtual or the reverse. See Instance Reclassification.
Data Member Redefinition
Class redefinition relating to data members includes changing the definition of a class by adding or deleting members, changing the value type of a data member, and changing the order of data members. (To change the name of a data member, you delete it and then add a new one with the desired name.) See Instance Reclassification.
Member Function Redefinition
There are only two kinds of member function-related changes that require schema evolution: changing the definition of a class by adding the first virtual function, and changing the definition of a class by removing the only virtual function. These modifications require schema evolution because they change the representation of any instances of the modified class. Other changes related to member functions have no effect on the layout of class instances, and so do not require schema evolution. See Instance Reclassification.
Class Deletion
In the case of class deletion, instance migration consists of the deletion of existing instances of the deleted classes. Any pointers typed as pointers to a deleted class are detected before instance initialization, and result in an err_schema_evolution exception. Any void* pointer to an instance of a deleted class (or pointer to a subobject of such an instance) is detected as an illegal pointer.
Instance Reclassification
As mentioned earlier, the schema evolution facility provides a special capability for reclassifying instances of a base class so that they become instances of classes derived from the base class. This form of instance migration is never actually required by a schema change, but it is often desirable.
Schema Changes Related to Data Members
The sections that follow consider the different types of schema modification related to data members. They are:
Notice that indirect instances of a modified class are migrated just as are direct instances. That is, if you change the definition of base class B, then instances of class D, derived from B, will be migrated just as are direct instances (if there are any) of B.
If the value type is a built-in, nonarray type (integral type, floating type, pointer type, reference type, enumeration type, or pointer to member type), it is initialized with the appropriate representation of 0. If the value type is a class, the field is initialized as if by a constructor that initializes each member to 0.
If the value type is an array type, each element of the array is initialized (for arrays of built-ins) with 0 or (for arrays of class instances) as if by a constructor that initializes each member to 0 for the array's element class. For arrays of arrays, these rules are applied recursively. In other words, an array is initialized by initializing each of its elements as if it were a separate data member.
As with all modified classes, the class with the new data member can have an associated transformer function that you supply. If you want, this function can overwrite these default initializations, supplying a value for the new field in whatever way meets your needs.
By default, pointers to members being removed result in an illegal pointer exception during evolution. You can, however, supply an illegal pointer handler to process the illegal pointer and resume evolution. See Illegal Pointers.
Changing the Value Type of a Data Member
When you change the value type of a data member, the schema evolution process changes the representation of any of its instances by adjusting the size of the member's associated storage (if necessary) and reinitializing that storage. How this storage is initialized depends on the new and old value types. Assignment-compatible value types
Old and new member declarations with assignment-compatible value types.

New value type is a built-in
Old and new member declarations with assignment-incompatible value types, where the new value type is a built-in.

New value type is a class
Old and new member declarations, where the new value type is a class.

Array values with compatible types
Old and new member declarations with array value types whose elements are assignment compatible.
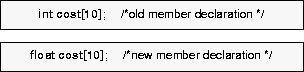
Array values with incompatible types
Old and new member declarations with array value types whose elements are not assignment compatible.
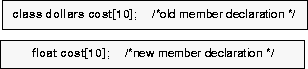
Non-array to array type
Old and new member declarations; the old value type is a nonarray type and the new value type is an array type.
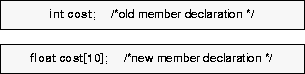
Changing the Order of Data Members
When you change the order of the data members defined by a class (by changing the order in which their declarations appear within the definition of the class), the schema evolution process changes the representation of any of its instances by reordering the storage fields associated with the members. Since there is no new storage created by this schema change, the issue of initialization does not arise. Summary of Data Member Changes Not Requiring Explicit Evolution
Note that you do not need to invoke schema evolution to make the following kinds of data member modifications:
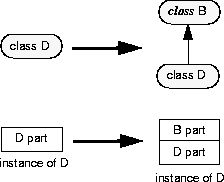
When the class D is modified to inherit from a base class, B, its instances must be modified to include a B part.
The instance initialization phase of schema evolution will add the B part to each instance of D, and initialize that part as if by a constructor that initializes each member to 0.
If you provide a transformer function for D, it will be run during the instance transformation phase.
Note that this category of schema change covers more cases than might be suggested by the illustration above.
In particular,
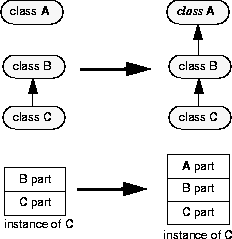
When you change the definition of B so that it inherits from A, instances of C (derived from B) must be migrated.
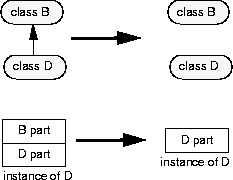
When the class D is modified so that it no longer inherits from a base class, B, its instances must be modified to remove the B part.
Pointers to the subobject being removed, if they are typed as B* rather than D*, result in an illegal pointer exception's being signaled during evolution. (Pointers typed as D* are, of course, automatically adjusted to point to the migrated instance of D.) The same is true for pointers (so typed) to data members of the deleted subobject.
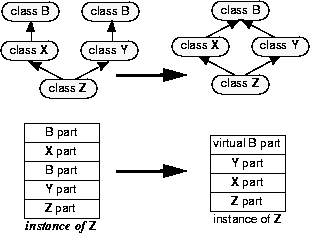
When you change both X and Y to inherit virtually from B, instances of Z (derived from both X and Y) are migrated so that they have only a single B part.
Similarly, if inheritance is changed from virtual to nonvirtual, every nonvirtual subobject introduced by the change is initialized as if by a constructor that sets each field to 0. So if X has a virtual base class, B, changing X to inherit nonvirtually from B eliminates a virtual B subobject from each instance of X and introduces a nonvirtual B subobject that is initialized as if by a constructor that sets each member to 0.
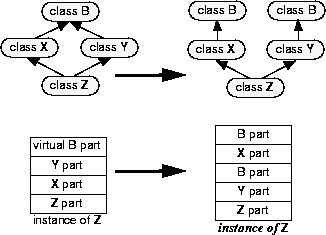
When you change either X or Y to inherit nonvirtually from B, instances of Z (derived from both X and Y) are migrated so that they have two B parts.
Note that an instance of a base class can be reclassified as an instance of any class derived from the base class, not just classes directly derived from it.
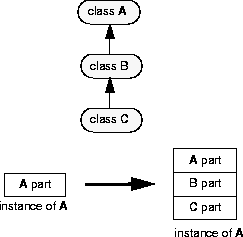
When you reclassify an instance of A so that it becomes an instance of C, it acquires two additional subobjects.
Updated: 03/31/98 15:31:20